从 Bundle Adjustment 到 VGGT - Brief History of Dense Reconstruction in Multi View Stereo (MVS)
一言以蔽之,Dense Reconstruction就是根据输入的RGB图像和稀疏重建结果重建出高密度点云。 其中包括深度图估计、点云融合及过滤操作。

# Colmap中的Dense Reconstruction
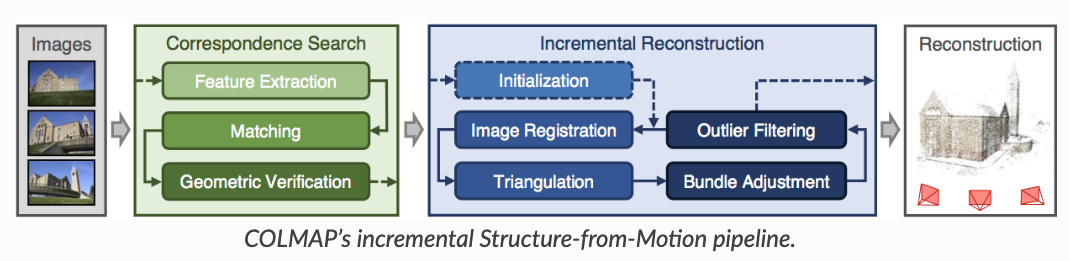
在《【摘录】相机位姿估计相关代码解读》的开头我们进行了相机位姿估计并生成了稀疏点云,还基于估计出的相机参数将输入图像扭回了针孔相机模式。 接下来即可在Colmap中进行Dense Reconstruction。
还记得image_undistorter生成了两个.sh文件?里面就写着Dense Reconstruction的例程。
run-colmap-geometric.sh:
# You must set $COLMAP_EXE_PATH to
# the directory containing the COLMAP executables.
$COLMAP_EXE_PATH/colmap patch_match_stereo \
--workspace_path . \
--workspace_format COLMAP \
--PatchMatchStereo.max_image_size 2000 \
--PatchMatchStereo.geom_consistency true
$COLMAP_EXE_PATH/colmap stereo_fusion \
--workspace_path . \
--workspace_format COLMAP \
--input_type geometric \
--output_path ./fused.ply
$COLMAP_EXE_PATH/colmap poisson_mesher \
--input_path ./fused.ply \
--output_path ./meshed-poisson.ply
$COLMAP_EXE_PATH/colmap delaunay_mesher \
--input_path . \
--input_type dense \
--output_path ./meshed-delaunay.ply
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
run-colmap-photometric.sh:
# You must set $COLMAP_EXE_PATH to
# the directory containing the COLMAP executables.
$COLMAP_EXE_PATH/colmap patch_match_stereo \
--workspace_path . \
--workspace_format COLMAP \
--PatchMatchStereo.max_image_size 2000 \
--PatchMatchStereo.geom_consistency false
$COLMAP_EXE_PATH/colmap stereo_fusion \
--workspace_path . \
--workspace_format COLMAP \
--input_type photometric \
--output_path ./fused.ply
$COLMAP_EXE_PATH/colmap poisson_mesher \
--input_path ./fused.ply \
--output_path ./meshed-poisson.ply
$COLMAP_EXE_PATH/colmap delaunay_mesher \
--input_path . \
--input_type dense \
--output_path ./meshed-delaunay.ply
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
其中的四个指令分别是:
patch_match_stereo深度估计: 利用 Patch Match 在输入图像之间进行Patch匹配从而估计深度。这一步会在stereo/depth_maps和stereo/normal_maps中生成深度图和法线图stereo_fusion多目融合: 每张深度图都对应一个点云,这一步把各图像的点云融合成一个点云poisson_mesher: 一种网格生成算法,使用 Poisson 表面重建生成彩色点云 Meshdelaunay_mesher: 一种网格生成算法,基于 Delaunay 三角剖分生成Delaunay Mesh
可以看到geometric和photometric就只有--PatchMatchStereo.geom_consistency和--input_type参数不一样。
在patch_match_stereo中,其深度一开始是随机赋值的,在对于纹理缺少的地方,无法获得准确深度信息而残留随机值,所以初始计算的深度图在纹理缺失的光滑表面是不光滑的。这里的--PatchMatchStereo.geom_consistency就是通过光学一致性和几何一致性约束,对初始深度图进行过滤。详情可见Pixelwise View Selection for Unstructured Multi-View Stereo
# Bundle Adjustment
Bundle Adjustment中文译为 光束法平差、束调整、捆集调整、捆绑调整 等等。
Bundle Adjustment的本质是一个优化模型,其目的是最小化重投影误差
所谓bundle,来源于bundle of light,其本意就是指的光束,这些光束指的是三维空间中的点投影到像平面上的光束,而重投影误差正是利用这些光束来构建的,因此称为光束法强调光束也正是描述其优化模型是如何建立的。剩下的就是平差,那什么是平差呢?借用一下百度词条 测量平差 中的解释吧。
由于测量仪器的精度不完善和人为因素及外界条件的影响,测量误差总是不可避免的。为了提高成果的质量,处理好这些测量中存在的误差问题,观测值的个数往往要多于确定未知量所必须观测的个数,也就是要进行多余观测。有了多余观测,势必在观测结果之间产生矛盾,测量平差的目的就在于消除这些矛盾而求得观测量的最可靠结果并评定测量成果的精度。测量平差采用的原理就是“最小二乘法”。
# 重投影误差
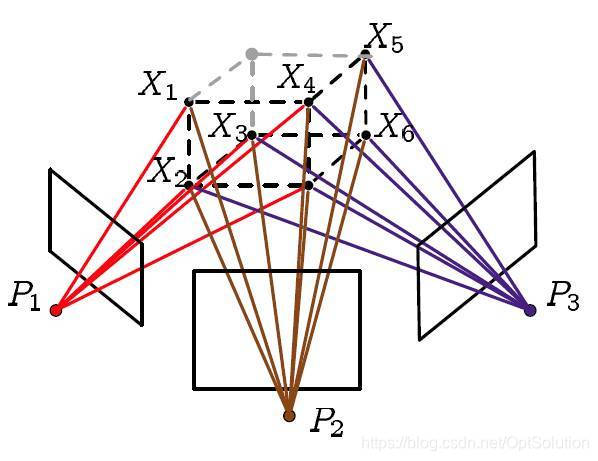
- 投影:利用这些图像对一些特征点进行三角定位(triangulation),计算特征点在三维空间中的位置
- 重投影:利用相机参数和投影计算得到的三维点的坐标,将这些三维点投影到相机成像平面上
- 重投影误差:输入图像上的像素点位置和其在重投影图像上的位置之差
设相机i的内参为Ki(已知)、外参为[Ri∣ti](优化变量)、点Xj(优化变量)在相机i中拍摄到的图像归一化坐标系上的坐标为[uij,vij](已知)。 则该点在重投影图像上的位置为z[u^ij,v^ij,1]T=Ki(RiXj+ti)。 于是重投影误差为:
E(Ti,Xj)=i∑j∑σij∣[u^ij,v^ij,1]−[uij,vij,1]∣=i∑j∑σij∣z1Ki(RiXj+ti)−[uij,vij,1]∣
其中当点Xj在相机i中有投影时σij=1,否则为σij=0。
于是Bundle Adjustment的优化问题为:
Ri,ti,XjminE(Ti,Xj)
求解方法:梯度下降法、Newton型方法、Gauss-Newton方法、Levenberg-Marquardt方法等
# 梯度下降法
懂得都懂,详略
最速下降法保证了每次迭代函数都是下降的,在初始点离最优点很远的时候刚开始下降的速度非常快,但是最速下降法的迭代方向是折线形的导致了收敛非常非常的慢。
# Newton型方法
现在先回顾一下中学数学,给定一个开口向上的一元二次函数,如何知道该函数何处最小?这个应该很容易就可以答上来了,对该函数求导,导数为0处就是函数最小处。Newton型方法也就是这种思想。
首先将函数利用泰勒展开到二次项:
f(x+Δx)≈f(x)+∇f(x)Δx+21ΔxTH(x)Δx
H为Hessian矩阵,是二次偏导矩阵。
也就是说Newton型方法将函数局部近似成一个二次函数进行迭代,令x在Δx方向上迭代直至收敛,接下来自然就对这个函数求导了:
f′(x)=δ→0limΔxf(x+Δx)−f(x)≈∇f(x)+H(x)Δx
于是优化问题为求x使得:
∇f(x)+H(x)Δx=0
Newton型方法收敛的时候特别快,尤其是对于二次函数而言一步就可以得到结果。但是该方法有个最大的缺点就是Hessian矩阵计算实在是太复杂了,并且Newton型方法的迭代并不像最速下降法一样保证每次迭代都是下降的。
# 其他方法
更多详情可见《Bundle Adjustment简述》
- Gauss-Newton方法:Gauss-Newton方法是一种求解非线性最小二乘问题的方法,其避免了求Hessian矩阵,并且在收敛的时候依旧很快。但是无法保证每次迭代的时候函数都是下降的。
- Gauss-Newton方法+稀疏矩阵Cholesky分解:Gauss-Newton方法中需要求解超定参数方程,通常矩阵分解的计算量是O(n3),面对BA这种超大规模的优化有点不太实用,而Cholesky分解在求解线性方程组中的效率约两倍于LU分解。
- Levenberg-Marquardt(LM)方法:LM方法又称阻尼最小二乘(DLS)方法,用于求解非线性最小二乘问题。LM方法就是在以上方法基础上的改进,通过参数的调整使得优化能在最速下降法和Gauss-Newton法之间自由的切换,在保证下降的同时也能保证快速收敛。
- 李群求解:详情可见《Bundle Adjustment原理及应用(附代码)》

# CVPR2023《DUSt3R: Geometric 3D Vision Made Easy》:不需要相机位姿输入的Dense Reconstruction
给定一个无约束的图像集合,即一组具有未知相机姿态和内参的照片,DUSt3R输出一组相应的 点图(pointmap) 和对应的 置信度图(confidence maps) ,从而可用于各种下游任务,例如相机参数估计、深度估计、3D重建等。
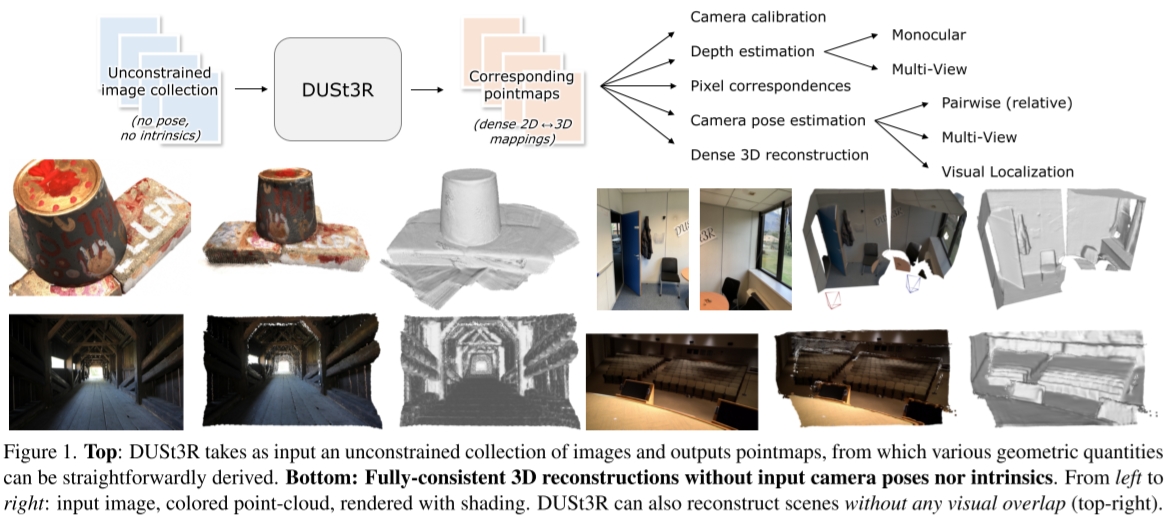
# 网络结构
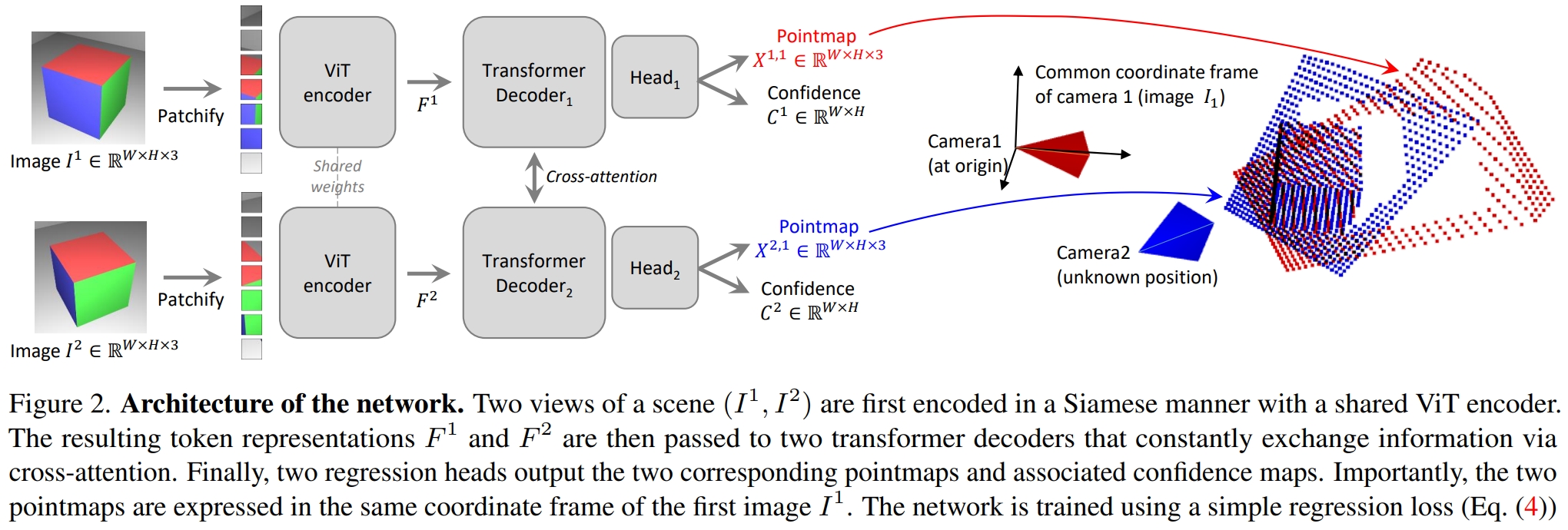
简言之就是 一个ViT提取特征、Transformer Decoder做Cross Attention、MLP Head输出pointmap和confidence map。
输入为两张图片切成Patch分别为I1,I2,输出为:
- pointmap X1,1,X2,1Rw×H×3: 图像上的每个点在三维空间中的位置
- confidence map C1,C2∈Rw×H: 图像上的每个点的置信度
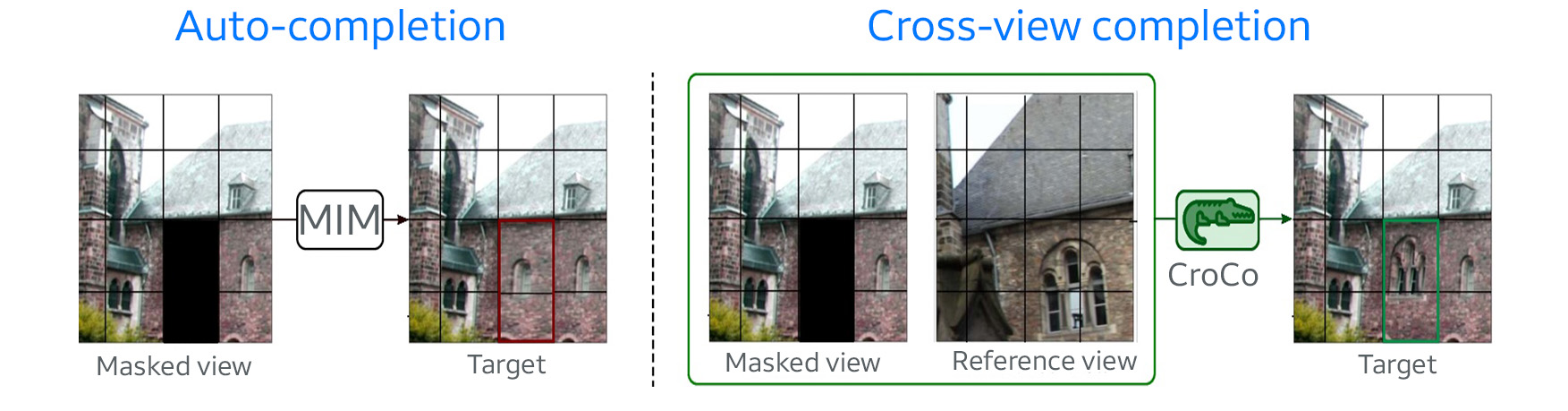
其中,Transformer Decoder使用CroCo中的预训练模型。 相关论文:CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion CroCo是一个Self-Supervised Pre-training的Cross-View Completion模型,根据一个视角中的图像对另一个视角中的图像进行补全:
其模型结构与DUSt3R类似,也是用ViT提取特征然后用Transformer Decoder做Cross Attention、Head输出结果:
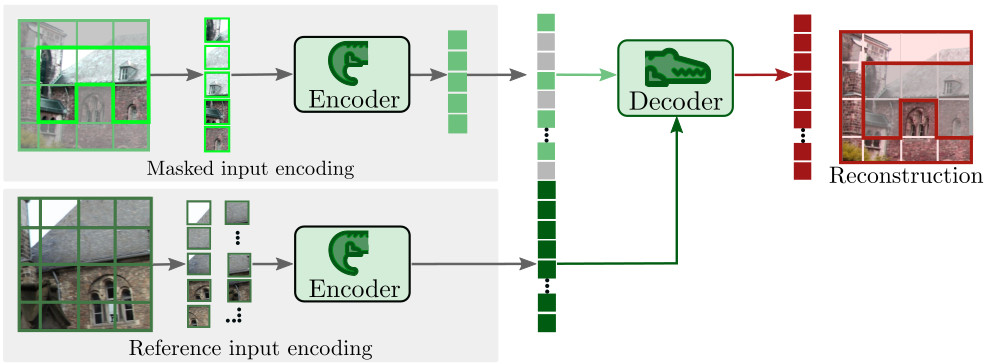
DUSt3R就改了最后的Head,让它从输出RGB图片变成输出pointmap和confidence map,前面预训练好的模型参数直接拿来就用,所以论文里说DUSt3R可以"benefit from powerful pretraining schemes"。
# 训练方式
# 3D Regression loss
两张输入图片的ground truth pointmap分别记为Xˉi1,1,Xˉi2,1,则两张图的 3D Regression loss ℓ(v,i)定义为:
ℓ(v,i)=∥∥∥∥∥z1Xiv,1−zˉ1Xˉiv,1∥∥∥∥∥,v∈{1,2}
其中,z=norm(Xi1,1,Xi2,1)、zˉ=norm(Xˉi1,1,Xˉi2,1)为缩放参数,用于处理3D空间中不同的尺度:
norm(X1,X2)=∣D1∣+∣D2∣∑i∥Xi1∥+∑i∥Xi2∥
# Confidence-aware loss
两张输入图片拍摄到的区域不一定完美重合,且可能会有深度不好确定的远景或眩光,因此图像上的某些区域深度不好确定。 confidence map就是为了应对这种情况。
为了训练模型输出的confidence map,作者定义了一个巧妙而合理的Confidence-aware loss:
Lconf=v∈{1,2}∑i∑Civ,1ℓ(v,i)−αlogCiv,1
可以看出,Confidence-aware loss由两项组成。 首先,Civ,1ℓ(v,i)强迫模型在ℓ(v,i)较高时给出较低置信度Ci,从而使得模型对自己预测的point map给出置信度;其次,模型总是给出较低的Civ,1也可以降低loss,因此再用一个正则化项αlogCiv,1强迫模型给出较高的Civ,1。
如此这般,模型就能学到预测point map的准确度,在不准确的地方给出较低的Civ,1。
# Global Alignment 全局对齐
DUSt3R的模型只能输入两张图片,但通常3D重建会拍很多张图片,比只拍两张效果要好。 为了和传统方法竞争,DUSt3R也要实现更多视角更高精度。 为了实现这一目的,本文作者提出了Global Alignment:
首先构造一个连通图G=(V,E)表示相机Pairwise的连通性,其中每个Pairwise e=(m,n)∈E表示输入图像Im,In有部分内容重合。
将每个视角都与其他所有有重合内容的视角输入到模型中推断一遍,得到多对pointmap和confidence map {((Xm,e,Cm,e),(Xm,e,Cn,e))∣e=(m,n)∈E},而后用梯度下降优化各视角下的pointmap χ={χv∣v∈V}使loss最小:
χ∗=χ,P,σargmine∈E∑v∈e∑i=1∑HWCiv,e∥χiv−σePeXiv,e∥
其中,σe>0和Pe∈R3×4分别表示Pairwise之间的缩放尺度和相对位姿;∑i=1HWCiv,e∥χiv−σePeXiv,e∥表示待优化的pointmap和推断出的pointmap之间的置信度加权差。 使该loss最小就是让χv与所有推断出的Xv,e的置信度加权差最小。
# CVPR2025 Best Paper 《VGGT: Visual Geometry Grounded Transformer》:Feed-Forward Dense Reconstruction的终极解决方案
DUST3R及其后续研究MAST3R是Dense Reconstruction领域的一大进步,其昭示了Transformer在三维重建领域的巨大潜力。 但他们的Transformer只能输入两张图片,重建过程仍然需要依赖后处理方法。 由此,作者提出了一个设想:
we ask if, finally, 3D tasks can be solved directly by a neural net- work, eschewing geometry post-processing almost entirely.
作者将相机位姿估计、多目深度估计、点云重建、3D点追踪这类三维重建任务概括为“从多视角图像估计3D属性”的任务,并思考这些问题能否用单个神经网络解决。 基于此思想,本文提出的VGGT进一步发掘了Transformer的潜力,验证了Transformer在多种三维重建任务上强大的泛化能力。
VGGT uses a shared backbone to predict all 3D quantities of interest together.
VGGT的思想类似大语言模型的预训练。 大语言模型中,Transformer在大量数据上训练后作为Backbone微调用于下游任务; 而VGGT同样在大量数据上训练,之后将其输出的特征应用于下游任务。
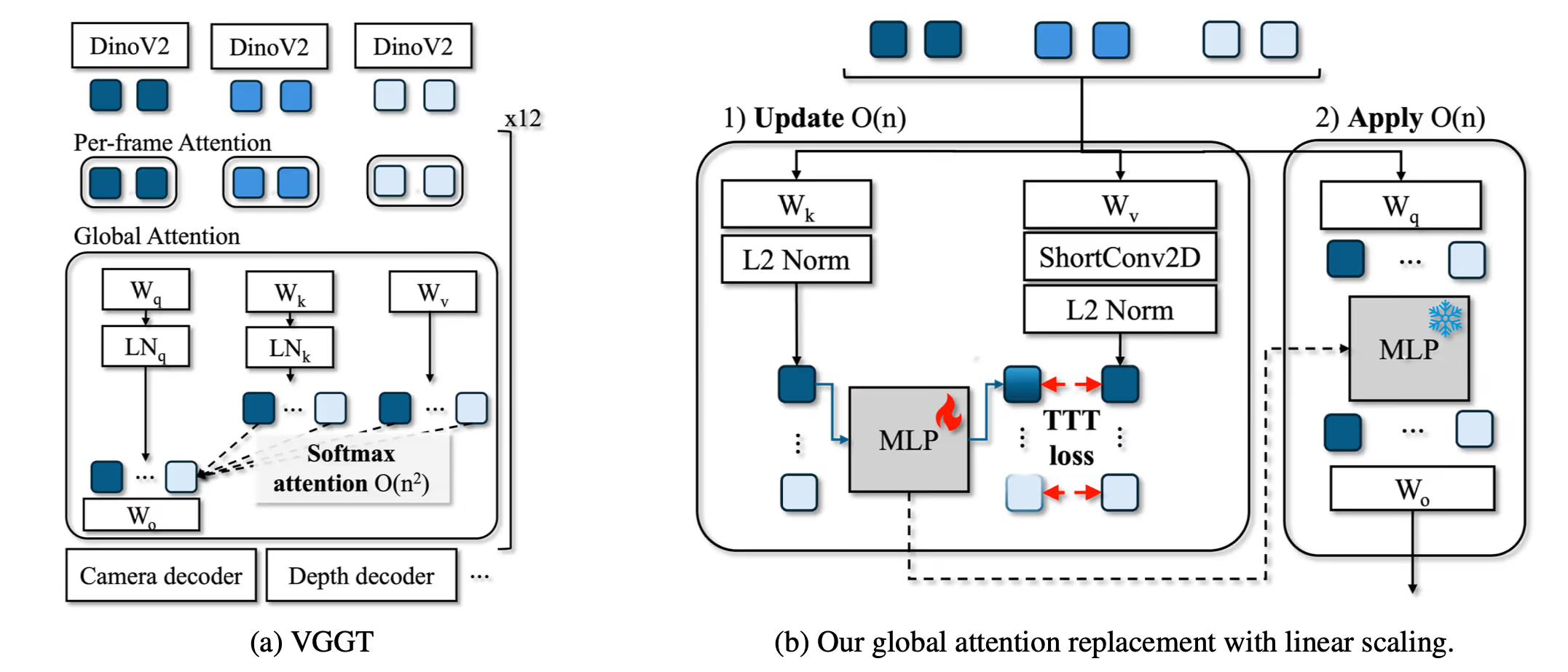
VGGT的结构大道至简,由一堆Transformer构成:
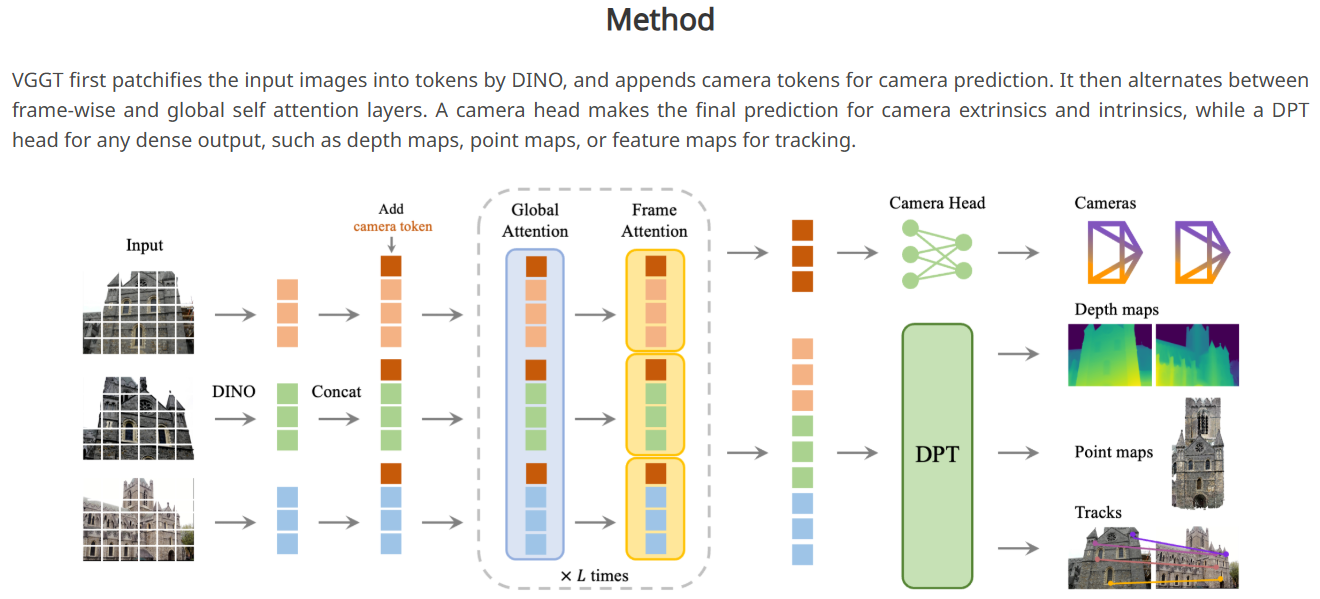
其中:
- 多视角图片经过一个DINO,每16x16的区域给出一个token
- 每个图像的token前面拼一个相机token和4个register token(这两种token都是可训练的nn.Parameter,每个图像拼的token都一样,关于register token的原理可参考Vision transformers need registers)
- Global Attention计算帧间注意力,Frame Attention计算帧内注意力,作者管这叫Alternating Attention
- 输出的相机token经过一个相机位姿head输出相机位姿,图像的token经过一个DPT Head输出像素级特征
- 像素级特征经过一个3x3的CNN输出深度图+三维点图+置信度,或经过CoTracker2实现点追踪
# Test-Time Training (TTT) 加速3D重建
2025以来,TTT已被引入3D重建中作为一种加速方法。 其核心思想和RNN很像,用一种隐式的中间状态代替VGGT等模型的全局注意力,每帧计算都将这个中间状态作为输入且对中间状态进行更新(时间复杂度O(n)),从而避免时间复杂度为O(n^2)的全局注意力,显著加速3D重建。
# CVPR2025 Oral Paper 《CUT3R: Continuous 3D Perception Model with Persistent State》:用RNN思想代替DUSt3R全局对齐实现长序列快速重建
# ICLR2026 Paper 《TTT3R: 3D Reconstruction as Test-Time Training》:用TTT更新CUT3R的中间状态
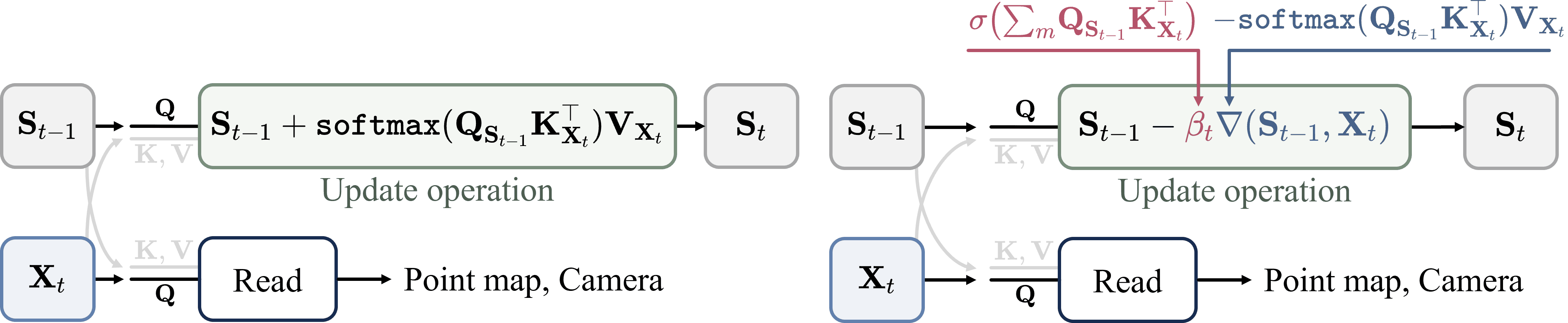
# CVPR2025 Oral Paper 《VGG-T³: Offline Feed-Forward 3D Reconstruction at Scale》:返祖-RNN思想+TTT代替VGGT全局注意力