主要参考论文: RepVGG: Making VGG-style ConvNets Great Again
主要思想
训练时的模型和运行时的模型结构不同,但相互等价。
例如在RepVGG方案中,训练时的模型是一个类似ResNet的网络结构,由于有Identity Branch所以有ResNet的训练稳定性优势;而推断时Identity Branch被等效为3x3卷积,与主干卷积核直接相加进而成为一个3x3卷积核。于是,RepVGG方案在训练时是一个稳定的ResNet,推断时又是一个高效的全卷积网络。
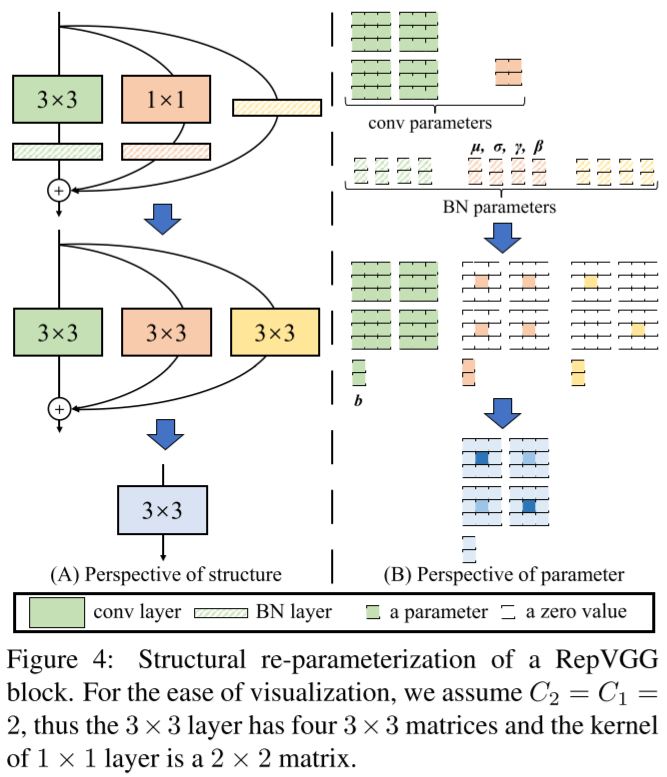
训练时的RepVGG
| 符号 | 含义 |
|---|
| W(3)∈RC1×C2×3×3 | 输入通道数为C1、输出通道数为C2,卷积核大小为3×3的卷积运算 |
| W(1)∈RC1×C2 | 输入通道数为C1、输出通道数为C2,卷积核大小为1×1的卷积运算 |
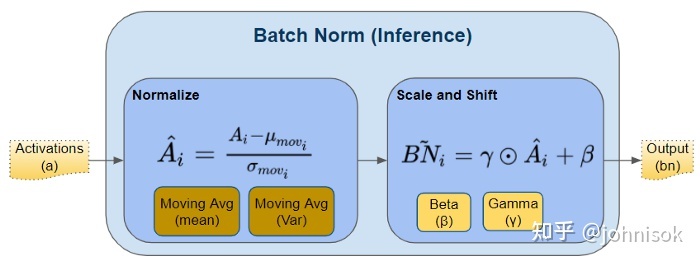
| bn(M,μ,σ,γ,β) | 输入为M、均值为μ、标准差为σ、缩放参数为γ和σ的BatchNorm层 |
设输入矩阵M:,:,:,:的四个维度依次对应样本编号、通道编号、图片宽度、图片长度,则BatchNorm层的计算可以表示为:
bn(M,μ,σ,γ,β):,i,:,:=(M:,i,:,:−μi)σiγi+βi
其中μ,σ分别表示BatchNorm层从训练中得到的均值、标准差,γ,β表示BatchNorm层学习到的缩放参数。
于是,训练时的RepVGG计算可以表示为:
M(2)=++bn(M(1)∗W(3),μ(3),σ(3),γ(3),β(3))bn(M(1)∗W(1),μ(1),σ(1),γ(1),β(1))bn(M(1),μ(0),σ(0),γ(0),β(0))
其中M(1)∗W(3)表示一个3×3卷积、M(1)∗W(1)表示一个1×1卷积、最后一项没有卷积操作即为Identity Branch;上标为(0),(1),(3)的μ,σ,γ,β分别表示在Identity Branch、3×3卷积和1×1卷积之后的BatchNorm层参数。
很明显,训练时的RepVGG Block是一个有两个卷积Branch和一个Identity Branch的网络,每个Branch上还都有一个BatchNorm。如下图所示:
推断时的RepVGG
将卷积运算带入上式中的BatchNorm:
bn(M∗W,μ,σ,γ,β):,i,:,:=(M:,i,:,:∗Wi,:,:,:−μi)σiγi+βi=M:,i,:,:∗σiγiWi,:,:,:−σiμiγi+βi
进而再带入RepVGG计算公式:
M:,i,:,:(2)==++++bn(M(1)∗W(3),μ(3),σ(3),γ(3),β(3)):,i,:,:bn(M(1)∗W(1),μ(1),σ(1),γ(1),β(1)):,i,:,:bn(M(1),μ(0),σ(0),γ(0),β(0)):,i,:,:M:,i,:,:(1)∗σi(3)γi(3)Wi,:,:,:(3)−σi(3)μi(3)γi(3)+βi(3)M:,i,:,:(1)∗σi(1)γi(1)Wi,:,:,:(1)−σi(1)μi(1)γi(1)+βi(1)M:,i,:,:(1)σi(0)γi(0)−σi(0)μi(0)γi(0)+βi(0)
而其中,一个1x1的卷积核可以表示为一个3x3的卷积核:
0 0 0
k -> 0 k 0
0 0 0
1
2
3
一个Identity Branch也可以表示为一个kernel为1的1x1的卷积核,进而也可以表示为一个3x3的卷积核。
于是,令W(3,1)表示与卷积W(1)等效的3x3的卷积、令W(3,I)表示与Identity Branch等效的3x3的卷积。那么RepVGG计算公式可进一步表示为:
M:,i,:,:(2)=++M:,i,:,:(1)∗σi(3)γi(3)Wi,:,:,:(3)−σi(3)μi(3)γi(3)+βi(3)M:,i,:,:(1)∗σi(1)γi(1)Wi,:,:,:(3,1)−σi(1)μi(1)γi(1)+βi(1)M:,i,:,:(1)∗σi(0)γi(0)Wi,:,:,:(3,I)−σi(0)μi(0)γi(0)+βi(0)
显然,最终可以合并为一个卷积:
M:,i,:,:(2)Wi,:,:,:′bi′=M:,i,:,:(1)∗Wi,:,:,:′+bi′=σi(3)γi(3)Wi,:,:,:(3)+σi(1)γi(1)Wi,:,:,:(3,1)+σi(0)γi(0)Wi,:,:,:(3,I)=βi(3)−σi(3)μi(3)γi(3)+βi(1)−σi(1)μi(1)γi(1)+βi(0)−σi(0)μi(0)γi(0)
最终合并所有通道可得:
M(2)W′b′=M(1)∗W′+b′=σ(3)γ(3)W(3)+σ(1)γ(1)W(3,1)+σ(0)γ(0)W(3,I)=β(3)−σ(3)μ(3)γ(3)+β(1)−σ(1)μ(1)γ(1)+β(0)−σ(0)μ(0)γ(0)
为什么选择3x3和1x1的做分支?
很显然,上面的公式可以很容易地推广到更大的卷积核上。3x3卷积核还可以配上5x5的7x7的这种“大一圈”的卷积核作为分支,那作者为什么只选了3x3卷积核?
首先很明显,推断时的网络结构中卷积核的大小就是训练时卷积核最大的那个分支的卷积核大小,所以设计训练网络时选择的卷积核大小要考虑到推断网络中卷积核大小对计算速度的影响。
而作者用cuDNN 7.5.0做了一个实验验证了推断网络中3x3的卷积核计算速度比较快:
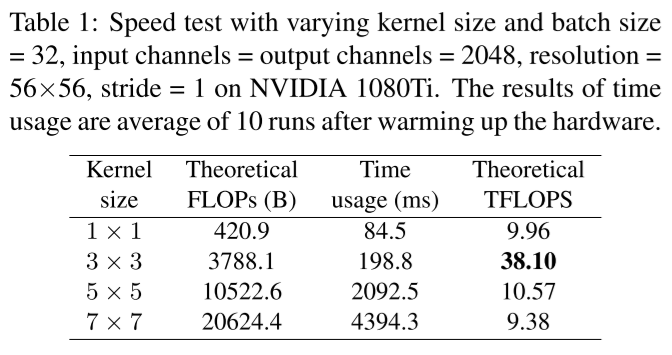
并且还解释了这是因为3x3卷积加速算法Winograd的广泛应用。
所以并不是3x3卷积有什么独特的性质,只是由于有个牛逼的加速算法广泛应用让3x3卷积在各种设备上都比较快。
Winograd算法: Andrew Lavin and Scott Gray. Fast algorithms for convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages
4013–4021, 2016. 3
- DiracNet: Sergey Zagoruyko and Nikos Komodakis. Diracnets: Training very deep neural networks without skip-connections.
arXiv preprint arXiv:1706.00388, 2017. 3, 7, 8
- Asym Conv Block (ACB): Xiaohan Ding, Yuchen Guo, Guiguang Ding, and Jungong Han. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE International Conference on Computer Vision, pages 1911–1920, 2019. 3, 7, 8
- DO-Conv: Jinming Cao, Yangyan Li, Mingchao Sun, Ying Chen, Dani Lischinski, Daniel Cohen-Or, Baoquan Chen, and Changhe Tu. Do-conv: Depthwise over-parameterized convolutional
layer. arXiv preprint arXiv:2006.12030, 2020. 3
- ExpandNet: Shuxuan Guo, Jose M Alvarez, and Mathieu Salzmann. Expandnets: Linear over-parameterization to train compact convolutional networks. Advances in Neural Information
Processing Systems, 33, 2020. 3