Transformer结构
原文:《Attention Is All You Need》
原文:The Illustrated Transformer
学Transformer之前请先理解《机器学习中的Attention机制》,Transformer会用到里面讲的自注意力和多头注意力机制。
先看论文里给出的结构:
![]()
一看,也是和《机器学习中的Attention机制》里介绍的RNN很相似的Encoder-Decoder结构。结合网上的各自解析我们可以知道,这个Encoder和Decoder都是由一个个基本单位叠起来的(可以看到原图中也写了这个“Nx”表示堆叠了多个像这样的单元)。
# Encoder单元
Encoder单元内部长这样:
![]()
输入的词经过自注意力+多头注意力之后经过一个全连接层。并且这自注意力和全连接层还吸收了残差网络的思想做了Add和Normalize:
![]()
注意这里Encoder有全连接层为什么还能输入任意长度?因为可以看到这个全连接层一次只处理一个词的输出,从《机器学习中的Attention机制》里介绍的自注意力+多头注意力可以知道每个词的自注意力输出的大小是固定的。
# Decoder单元
下面这图左边就是Decoder单元:
![]()
右边是Encoder单元的对堆叠方式,因为Self Attention和Feed Forward都没改变输入的尺寸,所以Encoder单元的输出可以直接作为下一个Encoder单元的输入,Decoder单元也是同样的原理堆叠方式也是一样。
此外,还可以看到,这个Decoder的中间有一个Attention层既接收了编码器的输入又接收了解码器前面的输入,那么这一层的K、Q、V都是多少?看这就知道了:
![]()
# 具体的运行过程
大佬做的动图,首先是把Encoder输出的K、V矩阵放进Decoder里,然后输入一个起始字符:
![]()
第一步的输出就是输出句子的一个词向量。
接下来的步骤就和RNN里的Decoder有异曲同工之妙,就是把之前的输出作为输入再输进Decoder里:
![]()
# 深入运行过程:Transformer中的三种Attention
Encoder 和 Decoder 虽然长的一样,但其内部计算 attention 的过程并不相同。
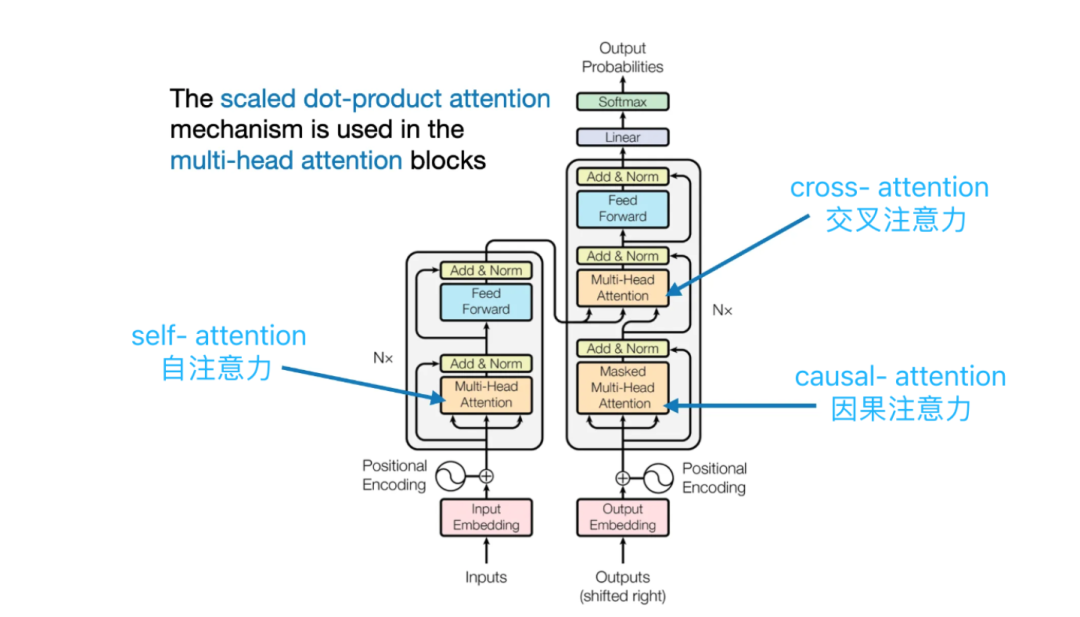
# Encoder: self-attention 自注意力, 又称 full attention
self-attention 是最基本最容易理解的 attention,在《机器学习中的Attention机制》中就讲的很清楚了,就是由输入的词向量si乘上3个矩阵WQ、WK、WV得到K、Q、V,即:
Qi=siWQKi=siWKVi=siWV
于是可以用矩阵运算一次算出一个句子里所有词的Ki、Qi、Vi:
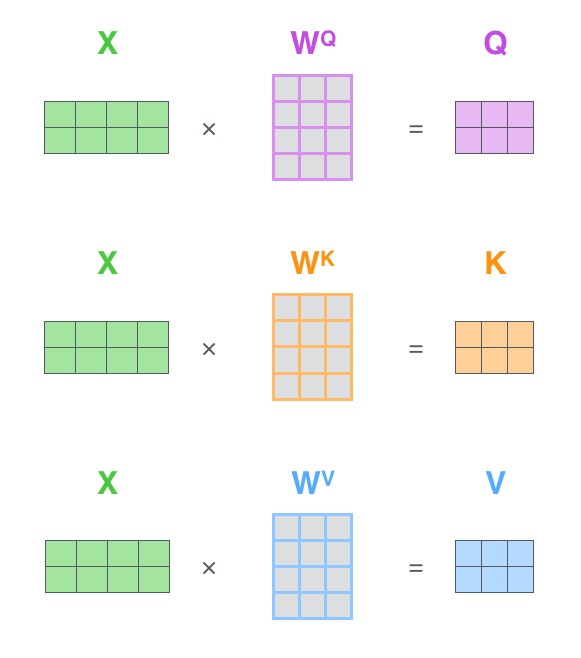
(图中的X表示所有的词向量si组成的矩阵)
最后,直接用矩阵计算出输出Attention值:
Attention(Q,K,V)=softmax(dkQKT)V
其中,dk是Ki、Qi、Vi的维度,除以dk是为了保证训练时梯度的稳定。
矩阵图示为:
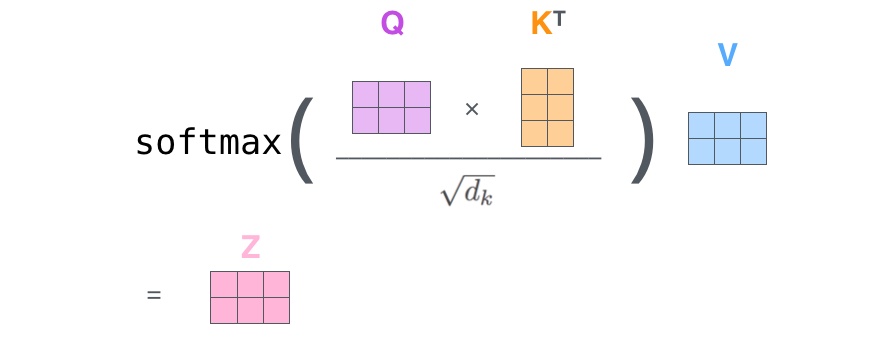
# Encoder 输出进入 Decoder 输入: cross-attention
cross-attention 和 self-attention 唯一的区别在于其K、V和Q来源于不同的计算过程。在Transformer中,K、V是Encoder的输出,Q是Decoder的输入经过一个masked self-attention计算得到。
其计算过程和 self-attention 完全一样:
Attention(Q,K,V)=softmax(dkQKT)V
疑问:
如果按照上面几张图的Decoder结构,Decoder模块的输出向量数量应该和输入的一样多,即输到最后的Linear+Softmax的矩阵大小是不断增长的不可能由一个固定的Linear+Softmax完成,是我漏看了什么吗?
解答:
- 编码器输入到解码器中的两个矩阵是作为K和V的,解码器生成的序列作为Q,它们的特征维数都相同。
- 于是在Attention(Q,K,V)=softmax(dkQKT)V中,QKT计算得到的矩阵长宽分别为Q的样本数(Q的行数)和K的样本数(KT的列数)。
- 而K的样本数和V的样本数相同,所以再乘上一个V之后的长宽就是Q的样本数和V的特征维数(等于Q的特征维数)。
- 所以解码器输出矩阵和输入Q的矩阵大小相同
# Decoder: masked self-attention 掩码自注意力, 又称 casual-attention 因果注意力
在原版 Transformer 中,masked self-attention 是 Decoder 中在 cross-attention 前对输入计算的 Attention。 Transformer 论文原图中在 Decoder 处的 Attention 标注为 Masked MultiHead Attention,说的就是 masked self-attention:
![]()
full attention 让输入的所有 token 之间都计算 attention,而 masked self-attention 和它相对,其的核心思想是让 token 只与其之前的 token 计算 attention。
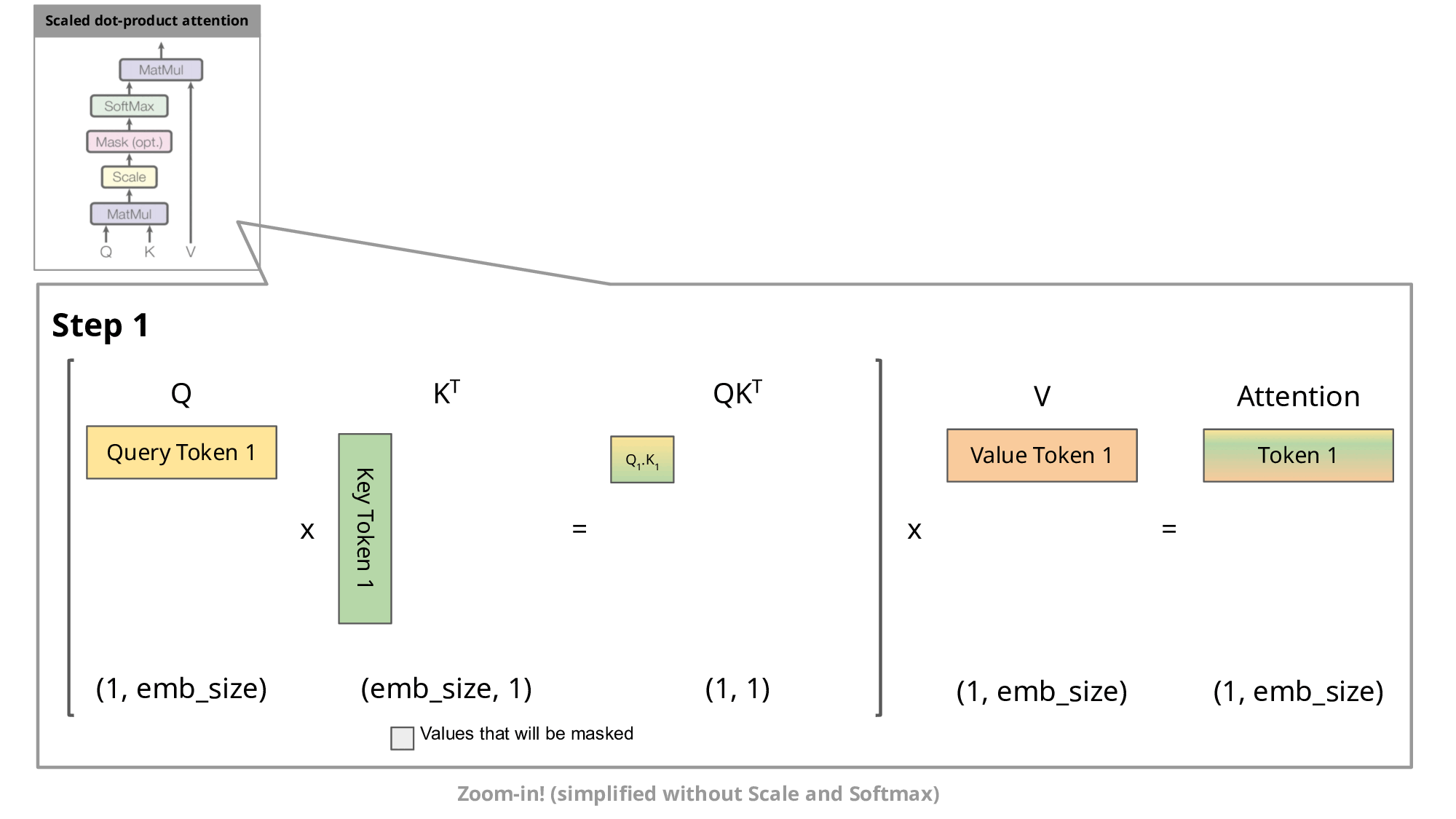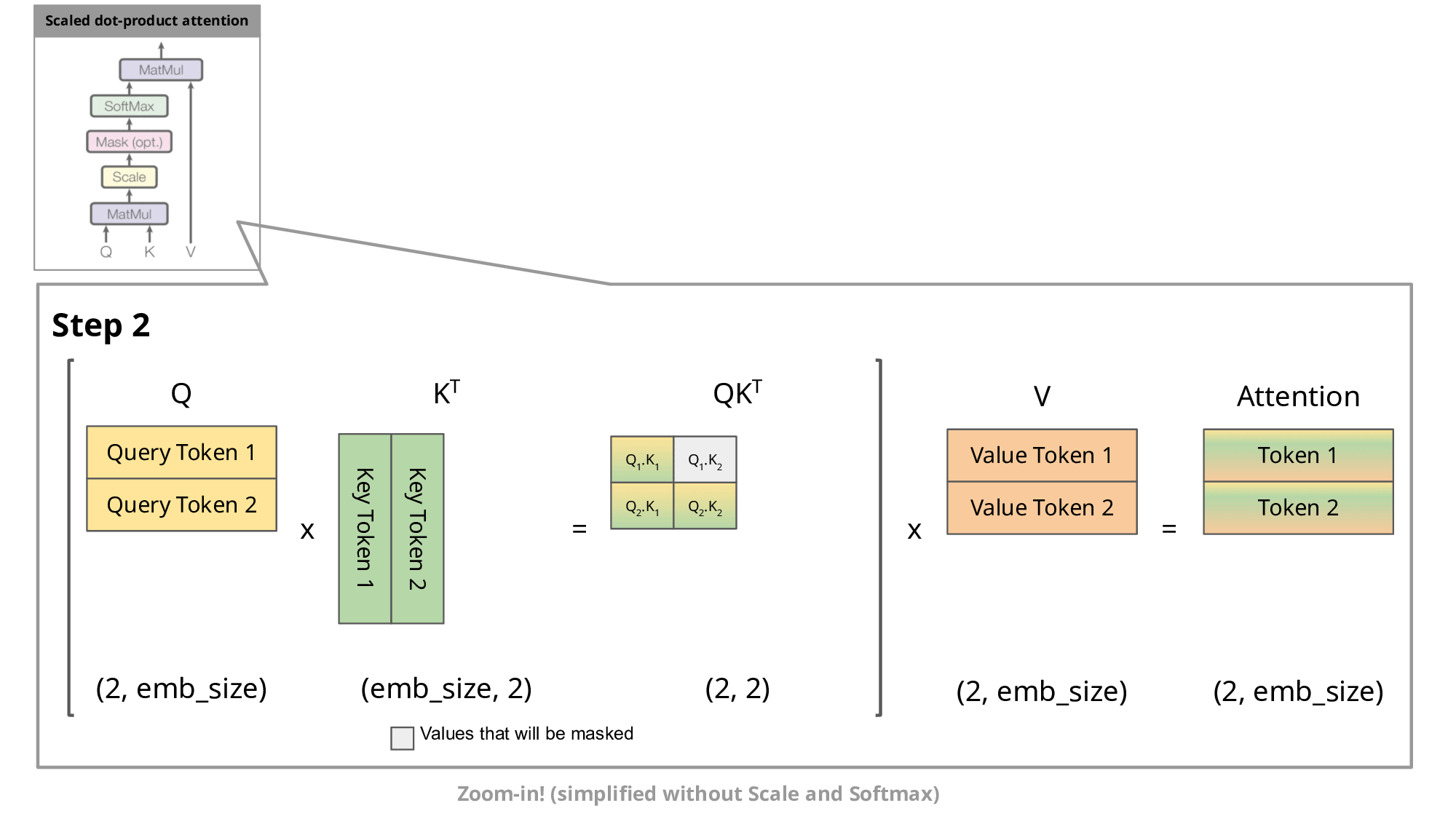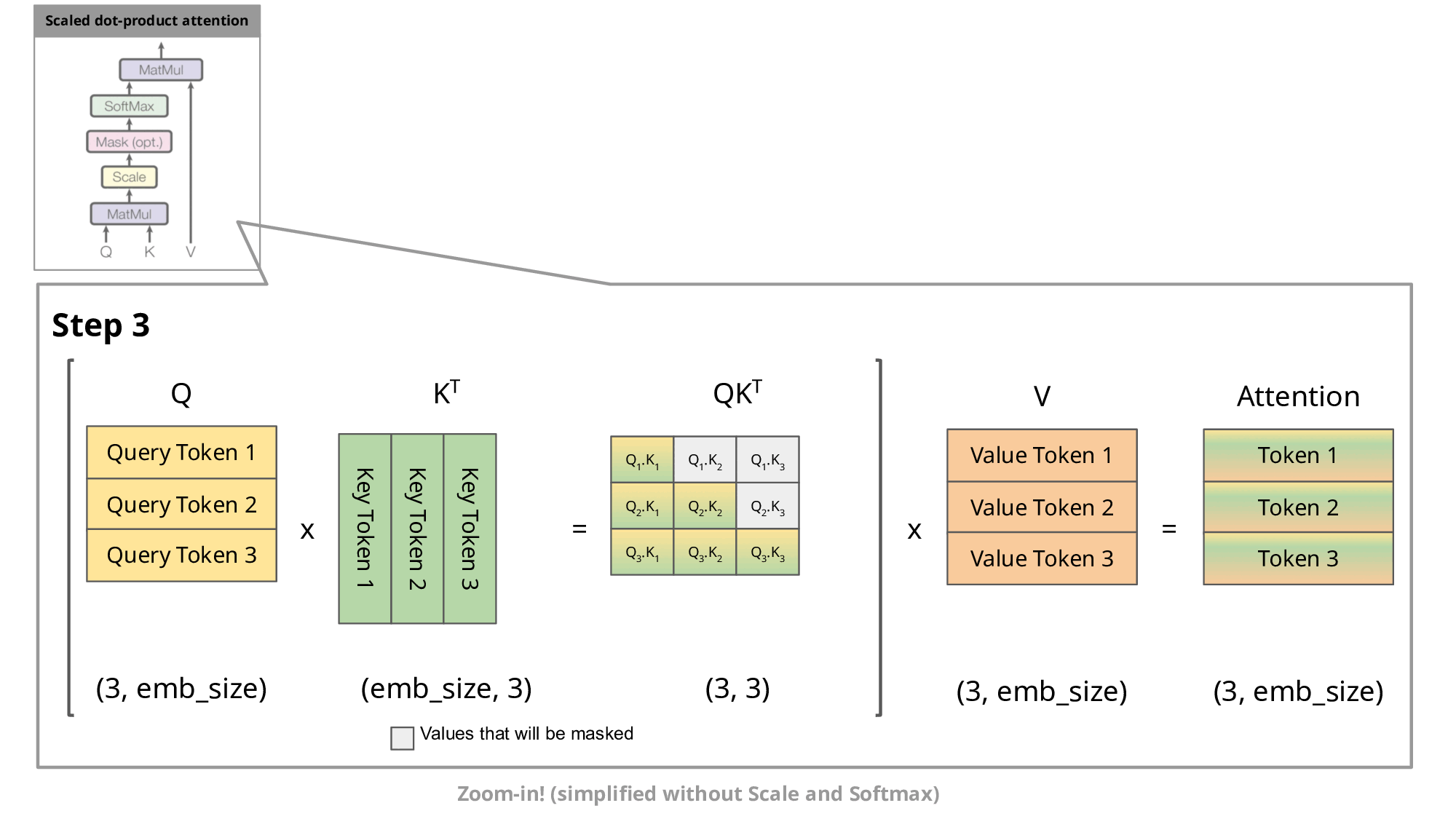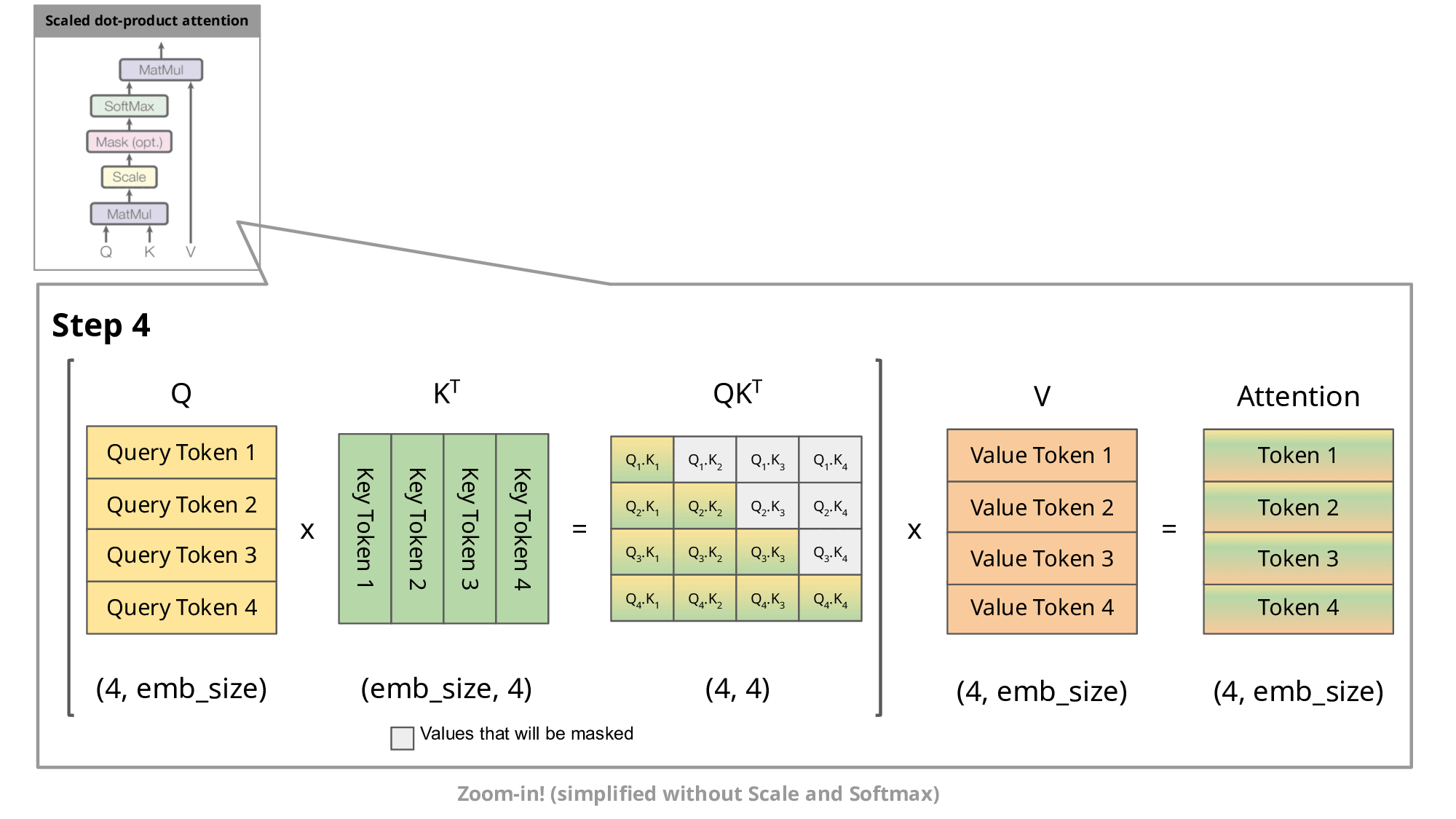
为什么要设计 masked self-attention ?网上的教程通常会说:
模型通常需要基于已经生成的词来预测下一个词。这种特性要求模型在训练时不能“看到”未来的信息。
但是下一个 token 本就是输出,在输入的时候下一个 token 还不存在呢,怎么“看到”未来的信息?
这些教程的表述给人一种感觉,会让人以为 masked self-attention 是为了提升训练效果而设计的。但实际上,这个 masked self-attention 主要是为了提升训练速度而设计的。
Encoder 的 full attention 每次输入一句话的所有 token 而输出一个 token 用于 cross-attention,因此对于 Encoder 来说,每个训练样本只需要一次前向和反向传播。 Decoder 当然也可以是一个 full attention,每次推理都对输入的所有 token 做 full attention 而输出下一个 token,问题在于 Decoder 的运行模式是多次运行出多个 token 拼成一句话,在训练时,这种运行模式就会导致一个训练样本中的每一个单词都要执行一次前向和反向传播,训练成本很高。
masked self-attention 就能解决这个问题。具体来说,
为了高效训练,我们不想每次只拿一个 prefix 训练,而是希望像 Encoder 那样一次 forward/backward 就完成这个 batch 里所有位置的 next-token loss 计算和一次参数更新。 这就需要模型在每个位置都产生一个 next-token prediction,并且这同时输出的每个位置的 prediction 得是和一个个输出的 prediction 是等价的才行。 这就是 masked self-attention 的设计目标。这个设计目标用公式表示为:
∀t≤TMaskedAttention(Q1:T,K1:T,V1:T)t=MaskedAttention(Q1:t,K1:t,V1:t)t(1)
用人话说就是:一次性输入整段所有 token Q1:T,K1:T,V1:T 算 masked self-attention 得到的第 t 个位置输出的 Attention 向量 MaskedAttention(Q1:T,K1:T,V1:T)t 等于只输入前缀 token Q1:t,K1:t,V1:t 算 masked self-attention 得到的最后位置的 Attention 向量 MaskedAttention(Q1:t,K1:t,V1:t)t,对所有 t∈T 成立。
masked self-attention 的运行流程如下:
第一步,对于第一个 token,Q,K,V 都是向量,等价于 full attention 只输入一个 token 时的特殊情况:
MaskedAttention(Q1:1,K1:1,V1:1)=softmax(dkQ1K1⊤)V1
对于后续的 token,Q,K,V成为矩阵。从第二个 token 开始:
MaskedAttention(Q1:2,K1:2,V1:2)=softmax⎝⎜⎛⎣⎢⎡dkQ1K1⊤dkQ2K1⊤0dkQ2K2⊤⎦⎥⎤⎠⎟⎞[V1V2]=⎣⎢⎢⎢⎢⎡softmax(dkQ1K1⊤)V1softmax([dkQ2K1⊤,dkQ2K2⊤])[V1V2]⎦⎥⎥⎥⎥⎤
其中softmax为按行进行softmax。以此类推:
MaskedAttention(Q1:t,K1:t,V1:t)=softmax⎝⎜⎜⎜⎜⎜⎜⎛⎣⎢⎢⎢⎢⎢⎢⎡dkQ1K1⊤dkQ2K1⊤⋮dkQtK1⊤0dkQ2K2⊤⋮dkQtK2⊤⋯⋯⋱⋯00⋮dkQtKt⊤⎦⎥⎥⎥⎥⎥⎥⎤⎠⎟⎟⎟⎟⎟⎟⎞⎣⎢⎢⎢⎢⎡V1V2⋮Vt⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡softmax(dkQ1K1⊤)V1softmax([dkQ2K1⊤,dkQ2K2⊤])[V1V2]⋯softmax([dkQtK1⊤,dkQtK2⊤,⋯,dkQtKt⊤])⎣⎢⎢⎢⎢⎡V1V2⋮Vt⎦⎥⎥⎥⎥⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
可以看出,输入更多的 token 并不影响MaskedAttention(Q1:t,K1:t,V1:t)中Q1:tK1:t⊤之前的行,因为在上三角部分的那些新输入的Qt,Kt,Vt有关的矩阵元素都被mask掉了。 这一性质用公式可以表达为:
MaskedAttention(Q1:t,K1:t,V1:t)1:t−1=MaskedAttention(Q1:t−1,K1:t−1,V1:t−1)
于是带入t=T推导:
MaskedAttention(Q1:T,K1:T,V1:T)1:T−1MaskedAttention(Q1:T,K1:T,V1:T)1:T−2⋯MaskedAttention(Q1:T,K1:T,V1:T)1:T−i=MaskedAttention(Q1:T−1,K1:T−1,V1:T−1)=(MaskedAttention(Q1:T,K1:T,V1:T)1:T−1)1:T−2=MaskedAttention(Q1:T−1,K1:T−1,V1:T−1)1:T−2=MaskedAttention(Q1:T−2,K1:T−2,V1:T−2)=MaskedAttention(Q1:T−i,K1:T−i,V1:T−i)0≤i≤T
最后带入t=T−i即得:
MaskedAttention(Q1:T,K1:T,V1:T)1:t=MaskedAttention(Q1:t,K1:t,V1:t)
公式(1)得证,设计目标达成。
此外,还可以推导出每次新增一个 token 后,输出矩阵中的新增行MaskedAttention(Q1:t,K1:t,V1:t)t的计算公式:
MaskedAttention(Q1:1,K1:1,V1:1)1MaskedAttention(Q1:2,K1:2,V1:2)2…MaskedAttention(Q1:t,K1:t,V1:t)t=softmax(dkQ1K1⊤)V1=1⋅V1=softmax([dkQ2K1⊤,dkQ2K2⊤])[V1V2]=softmax([dkQ2K1⊤,dkQ2K2⊤])1V1+softmax([dkQ2K1⊤,dkQ2K2⊤])2V2=softmax([dkQtK1⊤,dkQtK2⊤,⋯,dkQtKt⊤])⎣⎢⎢⎢⎢⎡V1V2⋮Vt⎦⎥⎥⎥⎥⎤=i=1∑tsoftmax([dkQtK1⊤,dkQtK2⊤,⋯,dkQtKt⊤])iVi
每当来一个新的 token,只需要按照这个公式计算新的一行即可,之前的行全不变。
如果用同样的符号写出 full attention:
Attention(Q1:T,K1:T,V1:T)t=i=1∑Tsoftmax([dkQtK1⊤,dkQtK2⊤,⋯,dkQtKT⊤])iVi
可以看出,每加一个 token QT,KT,VT不仅需要计算新的一行,还需要对之前的所有行都进行更新。 其中,对于第t行: 由于增加了一列dkQtKT⊤,从softmax这里就要重新计算softmax([dkQtK1⊤,dkQtK2⊤,⋯,dkQtKT⊤]),之后的求和也得重新计算,并且求和这里还多加一项softmax([dkQtK1⊤,dkQtK2⊤,⋯,dkQtKT⊤])TVT。
所以如果对已有计算结果做缓存,那 masked self-attention 会比 full attention 少很多计算量。
masked self-attention 还有一个很优美的性质:已知MaskedAttention(Q1:t,K1:t,V1:t)这里面每一行都是下一层 masked self-attention 的一个输入 token,每次加一个 token 都只需要加新的一行MaskedAttention(Q1:t,K1:t,V1:t)t,而不改变之前的行MaskedAttention(Q1:t−1,K1:t−1,V1:t−1),那在下一层看来就是之前的 token 输入全没变,只多加了一个新的 token,那这个 masked self-attention 也只需要加新的一行,而不改变之前的行,依此类推,串联的所有 masked self-attention 层都只需要计算新的一行,而不改变之前的行。
而 full attention 每次加一个 token 都要更新输出中的所有 token,这就改变了 full attention 的输入,所以下一层就得整个重新计算,难以优化。
masked self-attention 的这些独特性质带来一种新的加速方式:KV Cache。
继续学习:《KV Cache 原理》