让NeRF动起来
Howard Yin 2023-12-28 01:08:01 图形学
动态NeRF的目标:输入坐标x和时刻t输出颜色c和密度σ。
c,σ=M(x,t)
动态NeRF技术路线:
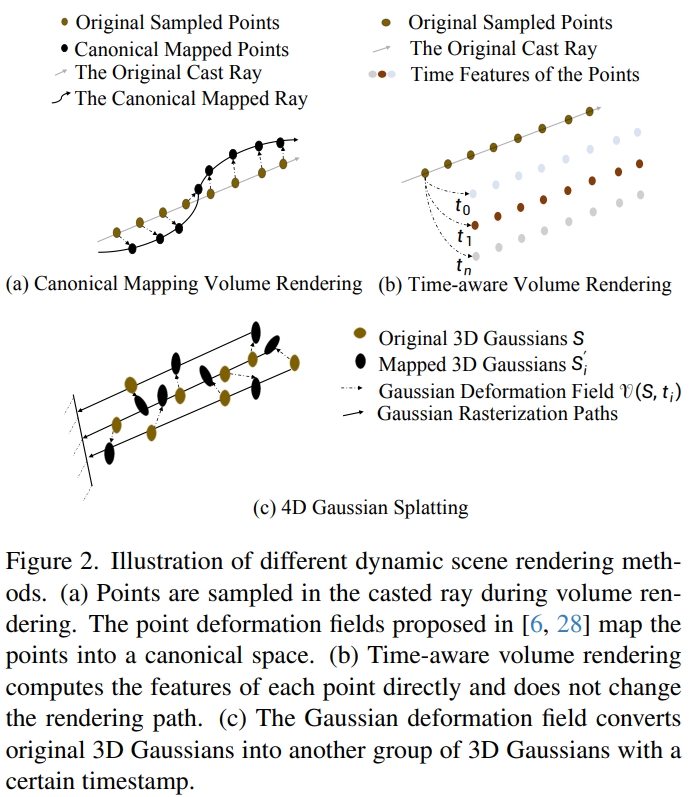
# Canonical-mapping volume rendering
基于NeRF的隐式表达难以修改,所以就修改Ray Marching采样路径,让采样路径变弯从而实现动态场景:
c,σ=M(x,t)=NeRF(x+Δx(t))
核心思想就是拟合这个Δx(t)。
- Fast Dynamic Radiance Fields with Time-Aware Neural Voxels
- Robust Dynamic Radiance Fields
- D-NeRF: Neural Radiance Fields for Dynamic Scenes
# Time-aware volume rendering
基于体素的显式表达不能移动位置,但是可以直接修改每个体素上的参数从而实现动态场景。
- Hexplane: A fast representation for dynamic scenes
- Neural 3D Video Synthesis From Multi-View Video
# 4D Gaussian Splatting
基于3D高斯点的显示表达可以直接移动位置。
核心思想:计算高斯点位移ΔG,然后直接对高斯点云G进行移动得到下一帧高斯点云G′:
G′ΔG=G+ΔG=F(G,t)
模型设计:
- spatial-temporal structure encoder 特征提取 f=H(G,t)
- G被表示为6个K-Planes
- 模型本体是一个MLP和6个multi-resolution K-Planes modules
- K-Planes: Explicit Radiance Fields in Space, Time, and Appearance
- multi-head Gaussian deformation decoder 根据特征输出形变 ΔG=D(f)
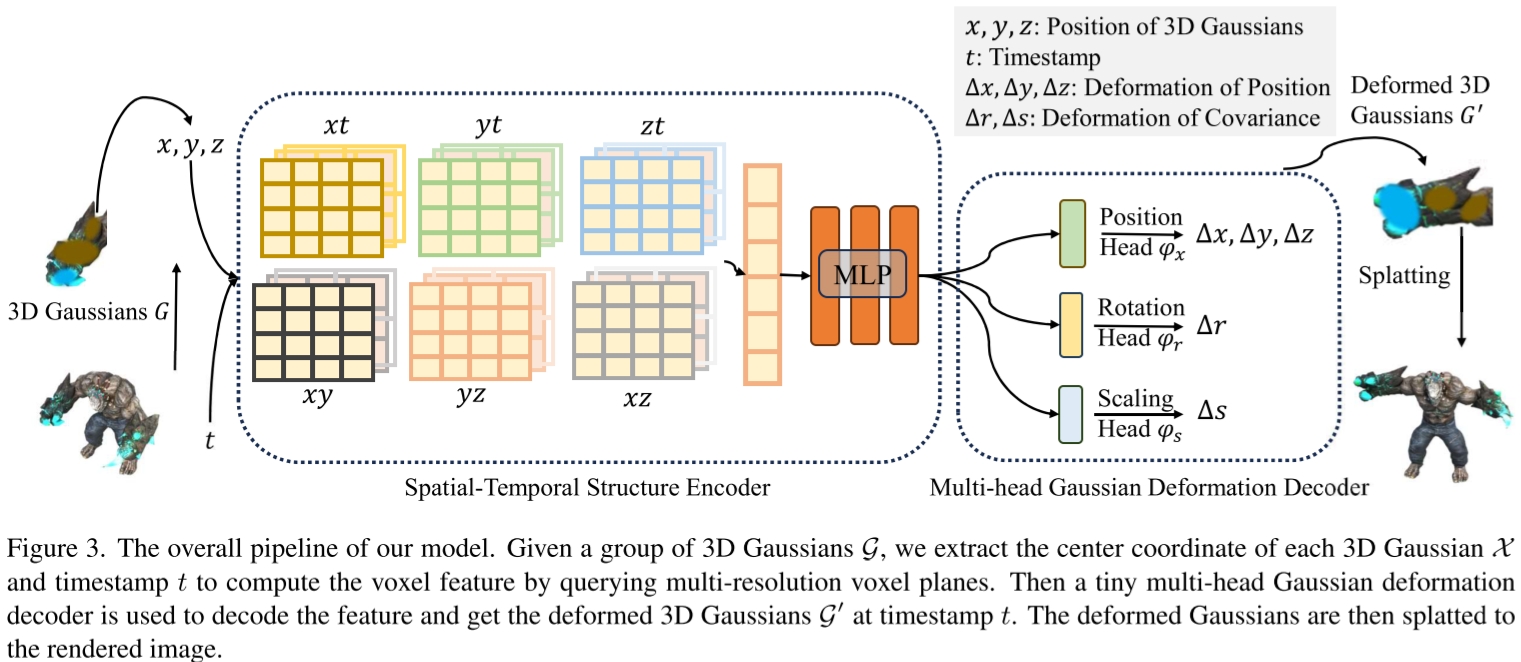
模型训练:L=I^−I+Ltv
- L1 color loss I^−I NeRF训练常见loss函数
- grid-based total-variational loss Ltv NeRF训练常见正则项,保证相邻顶点间的值尽量平滑
- 实验中的训练时间20min~1h