VGGT 原理解析
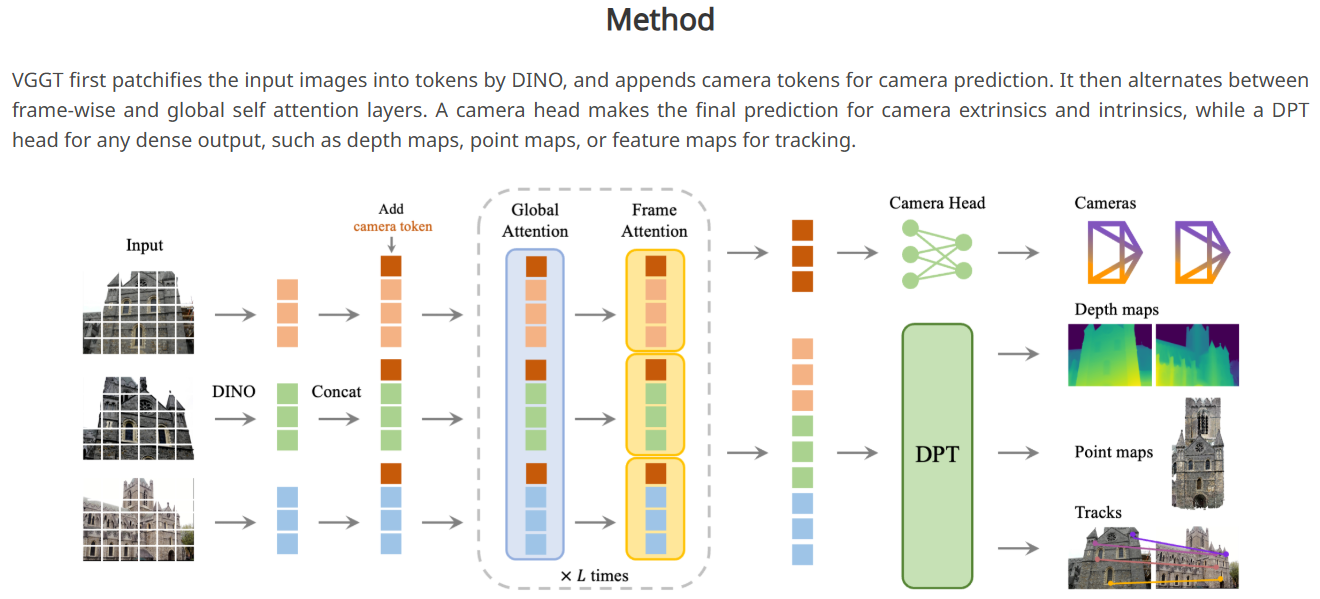
原版VGGT由一个骨干网络和4个Head构成:
self.aggregator = Aggregator(img_size=img_size, patch_size=patch_size, embed_dim=embed_dim)
self.camera_head = CameraHead(dim_in=2 * embed_dim) if enable_camera else None
self.point_head = DPTHead(dim_in=2 * embed_dim, output_dim=4, activation="inv_log", conf_activation="expp1") if enable_point else None
self.depth_head = DPTHead(dim_in=2 * embed_dim, output_dim=2, activation="exp", conf_activation="expp1") if enable_depth else None
self.track_head = TrackHead(dim_in=2 * embed_dim, patch_size=patch_size) if enable_track else None
2
3
4
5
6
其运行时输入为一批图片和一批用于track的查询点,输出为相机位置编码和深度+点云及其置信度,如果有track查询点输入还会输出查询点在每张图片上的像素位置、可见性及置信度:
def forward(self, images: torch.Tensor, query_points: torch.Tensor = None):
"""
Forward pass of the VGGT model.
Args:
images (torch.Tensor): Input images with shape [S, 3, H, W] or [B, S, 3, H, W], in range [0, 1].
B: batch size, S: sequence length, 3: RGB channels, H: height, W: width
query_points (torch.Tensor, optional): Query points for tracking, in pixel coordinates.
Shape: [N, 2] or [B, N, 2], where N is the number of query points.
Default: None
Returns:
dict: A dictionary containing the following predictions:
- pose_enc (torch.Tensor): Camera pose encoding with shape [B, S, 9] (from the last iteration)
- depth (torch.Tensor): Predicted depth maps with shape [B, S, H, W, 1]
- depth_conf (torch.Tensor): Confidence scores for depth predictions with shape [B, S, H, W]
- world_points (torch.Tensor): 3D world coordinates for each pixel with shape [B, S, H, W, 3]
- world_points_conf (torch.Tensor): Confidence scores for world points with shape [B, S, H, W]
- images (torch.Tensor): Original input images, preserved for visualization
If query_points is provided, also includes:
- track (torch.Tensor): Point tracks with shape [B, S, N, 2] (from the last iteration), in pixel coordinates
- vis (torch.Tensor): Visibility scores for tracked points with shape [B, S, N]
- conf (torch.Tensor): Confidence scores for tracked points with shape [B, S, N]
"""
# If without batch dimension, add it
if len(images.shape) == 4:
images = images.unsqueeze(0)
if query_points is not None and len(query_points.shape) == 2:
query_points = query_points.unsqueeze(0)
aggregated_tokens_list, patch_start_idx = self.aggregator(images)
predictions = {}
with torch.cuda.amp.autocast(enabled=False):
if self.camera_head is not None:
pose_enc_list = self.camera_head(aggregated_tokens_list)
predictions["pose_enc"] = pose_enc_list[-1] # pose encoding of the last iteration
predictions["pose_enc_list"] = pose_enc_list
if self.depth_head is not None:
depth, depth_conf = self.depth_head(
aggregated_tokens_list, images=images, patch_start_idx=patch_start_idx
)
predictions["depth"] = depth
predictions["depth_conf"] = depth_conf
if self.point_head is not None:
pts3d, pts3d_conf = self.point_head(
aggregated_tokens_list, images=images, patch_start_idx=patch_start_idx
)
predictions["world_points"] = pts3d
predictions["world_points_conf"] = pts3d_conf
if self.track_head is not None and query_points is not None:
track_list, vis, conf = self.track_head(
aggregated_tokens_list, images=images, patch_start_idx=patch_start_idx, query_points=query_points
)
predictions["track"] = track_list[-1] # track of the last iteration
predictions["vis"] = vis
predictions["conf"] = conf
if not self.training:
predictions["images"] = images # store the images for visualization during inference
return predictions
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
VGGT的结构决定了它只能输入固定尺寸的图片。
原版VGGT参数输入尺寸为518x518,patch_size为14x14。
在原版代码中,对于任意尺寸的图片,在输入VGGT之前是先由load_and_preprocess_images_squarepadding为正方形再缩放到1024x1024,再在run_VGGT里缩放到518x518。
# Aggregator 结构解析
# patch_embed
图片输入先经过一个patch_embed:
B, S, C_in, H, W = images.shape
if C_in != 3:
raise ValueError(f"Expected 3 input channels, got {C_in}")
# Normalize images and reshape for patch embed
images = (images - self._resnet_mean) / self._resnet_std
# Reshape to [B*S, C, H, W] for patch embedding
images = images.view(B * S, C_in, H, W)
patch_tokens = self.patch_embed(images)
if isinstance(patch_tokens, dict):
patch_tokens = patch_tokens["x_norm_patchtokens"]
2
3
4
5
6
7
8
9
10
11
12
13
14
这个patch_embed就是DINOv2或者卷积:
if "conv" in patch_embed:
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=3, embed_dim=embed_dim)
else:
vit_models = {
"dinov2_vitl14_reg": vit_large,
"dinov2_vitb14_reg": vit_base,
"dinov2_vits14_reg": vit_small,
"dinov2_vitg2_reg": vit_giant2,
}
self.patch_embed = vit_models[patch_embed](
img_size=img_size,
patch_size=patch_size,
num_register_tokens=num_register_tokens,
interpolate_antialias=interpolate_antialias,
interpolate_offset=interpolate_offset,
block_chunks=block_chunks,
init_values=init_values,
)
# Disable gradient updates for mask token
if hasattr(self.patch_embed, "mask_token"):
self.patch_embed.mask_token.requires_grad_(False)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# camera_token和register_token
再拿两个camera_token和register_token给拼在patch_embed后面:
_, P, C = patch_tokens.shape
# Expand camera and register tokens to match batch size and sequence length
camera_token = slice_expand_and_flatten(self.camera_token, B, S)
register_token = slice_expand_and_flatten(self.register_token, B, S)
# Concatenate special tokens with patch tokens
tokens = torch.cat([camera_token, register_token, patch_tokens], dim=1)
2
3
4
5
6
7
8
这里的slice_expand_and_flatten就是根据patch_embed的尺寸把token_tensor复制几遍:
def slice_expand_and_flatten(token_tensor, B, S):
"""
Processes specialized tokens with shape (1, 2, X, C) for multi-frame processing:
1) Uses the first position (index=0) for the first frame only
2) Uses the second position (index=1) for all remaining frames (S-1 frames)
3) Expands both to match batch size B
4) Concatenates to form (B, S, X, C) where each sequence has 1 first-position token
followed by (S-1) second-position tokens
5) Flattens to (B*S, X, C) for processing
Returns:
torch.Tensor: Processed tokens with shape (B*S, X, C)
"""
# Slice out the "query" tokens => shape (1, 1, ...)
query = token_tensor[:, 0:1, ...].expand(B, 1, *token_tensor.shape[2:])
# Slice out the "other" tokens => shape (1, S-1, ...)
others = token_tensor[:, 1:, ...].expand(B, S - 1, *token_tensor.shape[2:])
# Concatenate => shape (B, S, ...)
combined = torch.cat([query, others], dim=1)
# Finally flatten => shape (B*S, ...)
combined = combined.view(B * S, *combined.shape[2:])
return combined
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这两个camera_token和register_token就是两个可训练的nn.Parameter:
# Note: We have two camera tokens, one for the first frame and one for the rest
# The same applies for register tokens
self.camera_token = nn.Parameter(torch.randn(1, 2, 1, embed_dim))
self.register_token = nn.Parameter(torch.randn(1, 2, num_register_tokens, embed_dim))
2
3
4
并且经过normal_初始化参数:
# Initialize parameters with small values
nn.init.normal_(self.camera_token, std=1e-6)
nn.init.normal_(self.register_token, std=1e-6)
2
3
所以,这两个camera_token和register_token就是把可训练的两个token拼接在图片的patch_embed后面输入给transformer,每张图片后面都拼了一个相同的token。
# patch位置信息
接下来获取patch的位置信息:
pos = None
if self.rope is not None:
pos = self.position_getter(B * S, H // self.patch_size, W // self.patch_size, device=images.device)
if self.patch_start_idx > 0:
# do not use position embedding for special tokens (camera and register tokens)
# so set pos to 0 for the special tokens
pos = pos + 1
pos_special = torch.zeros(B * S, self.patch_start_idx, 2).to(images.device).to(pos.dtype)
pos = torch.cat([pos_special, pos], dim=1)
2
3
4
5
6
7
8
9
10
其实就是每个patch在图像上的坐标:
class PositionGetter:
"""Generates and caches 2D spatial positions for patches in a grid.
This class efficiently manages the generation of spatial coordinates for patches
in a 2D grid, caching results to avoid redundant computations.
Attributes:
position_cache: Dictionary storing precomputed position tensors for different
grid dimensions.
"""
def __init__(self):
"""Initializes the position generator with an empty cache."""
self.position_cache: Dict[Tuple[int, int], torch.Tensor] = {}
def __call__(self, batch_size: int, height: int, width: int, device: torch.device) -> torch.Tensor:
"""Generates spatial positions for a batch of patches.
Args:
batch_size: Number of samples in the batch.
height: Height of the grid in patches.
width: Width of the grid in patches.
device: Target device for the position tensor.
Returns:
Tensor of shape (batch_size, height*width, 2) containing y,x coordinates
for each position in the grid, repeated for each batch item.
"""
if (height, width) not in self.position_cache:
y_coords = torch.arange(height, device=device)
x_coords = torch.arange(width, device=device)
positions = torch.cartesian_prod(y_coords, x_coords)
self.position_cache[height, width] = positions
cached_positions = self.position_cache[height, width]
return cached_positions.view(1, height * width, 2).expand(batch_size, -1, -1).clone()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# Attention计算
经过多个Attention模块,每个Attention模块里都有几个全局attention和帧内attention子模块,根据aa_order决定是全局attention还是帧内attention,最后output_list输出attention后的所有token:
# update P because we added special tokens
_, P, C = tokens.shape
frame_idx = 0
global_idx = 0
output_list = []
for _ in range(self.aa_block_num):
for attn_type in self.aa_order:
if attn_type == "frame":
tokens, frame_idx, frame_intermediates = self._process_frame_attention(
tokens, B, S, P, C, frame_idx, pos=pos
)
elif attn_type == "global":
tokens, global_idx, global_intermediates = self._process_global_attention(
tokens, B, S, P, C, global_idx, pos=pos
)
else:
raise ValueError(f"Unknown attention type: {attn_type}")
for i in range(len(frame_intermediates)):
# concat frame and global intermediates, [B x S x P x 2C]
concat_inter = torch.cat([frame_intermediates[i], global_intermediates[i]], dim=-1)
output_list.append(concat_inter)
del concat_inter
del frame_intermediates
del global_intermediates
return output_list, self.patch_start_idx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
默认值为一个帧内加一个全局Attention:
aa_order=["frame", "global"]
帧内Attention和全局Attention模型结构都一样:
self.frame_blocks = nn.ModuleList(
[
block_fn(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
proj_bias=proj_bias,
ffn_bias=ffn_bias,
init_values=init_values,
qk_norm=qk_norm,
rope=self.rope,
)
for _ in range(depth)
]
)
self.global_blocks = nn.ModuleList(
[
block_fn(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
proj_bias=proj_bias,
ffn_bias=ffn_bias,
init_values=init_values,
qk_norm=qk_norm,
rope=self.rope,
)
for _ in range(depth)
]
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
区别在于推断时token的重排方式不一样:
def _process_frame_attention(self, tokens, B, S, P, C, frame_idx, pos=None):
"""
Process frame attention blocks. We keep tokens in shape (B*S, P, C).
"""
# If needed, reshape tokens or positions:
if tokens.shape != (B * S, P, C):
tokens = tokens.view(B, S, P, C).view(B * S, P, C)
if pos is not None and pos.shape != (B * S, P, 2):
pos = pos.view(B, S, P, 2).view(B * S, P, 2)
intermediates = []
# by default, self.aa_block_size=1, which processes one block at a time
for _ in range(self.aa_block_size):
if self.training:
tokens = checkpoint(self.frame_blocks[frame_idx], tokens, pos, use_reentrant=self.use_reentrant)
else:
tokens = self.frame_blocks[frame_idx](tokens, pos=pos)
frame_idx += 1
intermediates.append(tokens.view(B, S, P, C))
return tokens, frame_idx, intermediates
def _process_global_attention(self, tokens, B, S, P, C, global_idx, pos=None):
"""
Process global attention blocks. We keep tokens in shape (B, S*P, C).
"""
if tokens.shape != (B, S * P, C):
tokens = tokens.view(B, S, P, C).view(B, S * P, C)
if pos is not None and pos.shape != (B, S * P, 2):
pos = pos.view(B, S, P, 2).view(B, S * P, 2)
intermediates = []
# by default, self.aa_block_size=1, which processes one block at a time
for _ in range(self.aa_block_size):
if self.training:
tokens = checkpoint(self.global_blocks[global_idx], tokens, pos, use_reentrant=self.use_reentrant)
else:
tokens = self.global_blocks[global_idx](tokens, pos=pos)
global_idx += 1
intermediates.append(tokens.view(B, S, P, C))
return tokens, global_idx, intermediates
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
注意这两个函数唯一的区别在于开头几行:
def _process_frame_attention(self, tokens, B, S, P, C, frame_idx, pos=None):
......
if tokens.shape != (B * S, P, C):
tokens = tokens.view(B, S, P, C).view(B * S, P, C)
if pos is not None and pos.shape != (B * S, P, 2):
pos = pos.view(B, S, P, 2).view(B * S, P, 2)
......
def _process_global_attention(self, tokens, B, S, P, C, global_idx, pos=None):
......
if tokens.shape != (B, S * P, C):
tokens = tokens.view(B, S, P, C).view(B, S * P, C)
if pos is not None and pos.shape != (B, S * P, 2):
pos = pos.view(B, S, P, 2).view(B, S * P, 2)
......
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
帧内Attention的batch维是B*S,序列长度是P(单帧内部token),因此每个batch是在同一帧内计算attention。
全局Attention的batch 维是B,序列长度是S*P(所有帧token串起来),因此每个batch是在所有帧的所有token间计算attention。
# CameraHead:迭代式的相机参数细化
输入是 aggregator 输出的最后一层 token([B,S,P,2C]),CameraHead 只取第 0 个 token(相机 token),得到 pose_tokens: [B,S,2C],目标输出是每帧 9 维相机编码:[T(3), quat(4), FoV(2)]:
def forward(self, aggregated_tokens_list: list, num_iterations: int = 4) -> list:
"""
Forward pass to predict camera parameters.
Args:
aggregated_tokens_list (list): List of token tensors from the network;
the last tensor is used for prediction.
num_iterations (int, optional): Number of iterative refinement steps. Defaults to 4.
Returns:
list: A list of predicted camera encodings (post-activation) from each iteration.
"""
# Use tokens from the last block for camera prediction.
tokens = aggregated_tokens_list[-1]
# Extract the camera tokens
pose_tokens = tokens[:, :, 0]
pose_tokens = self.token_norm(pose_tokens)
pred_pose_enc_list = self.trunk_fn(pose_tokens, num_iterations)
return pred_pose_enc_list
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
CameraHead.trunk_fn是CameraHead的核心功能,其包含迭代增量式相机回归。
下面是对 trunk_fn 迭代细化机制的逐步解读。
# 总览
trunk_fn 的设计思想来自 DiT(Diffusion Transformer)中的 AdaLN(Adaptive Layer Norm)调制 和 RAFT 中的 迭代增量更新。它不是一次性回归出相机参数,而是每一轮都用"当前估计"去调制 token,然后预测一个增量,逐步逼近真实值。
# Step 0:初始化
B, S, C = pose_tokens.shape # B=batch, S=帧数, C=2048
pred_pose_enc = None # 还没有任何相机估计
pred_pose_enc_list = [] # 收集每轮输出
2
3
pose_tokens 是 aggregator 输出的 camera token(每帧 1 个),经过 LayerNorm 后传入。它编码了"这个场景中每帧的相机应该是什么"的全局信息,但还没有被解码成具体的 9D 参数。
接下来运行多轮:
for _ in range(num_iterations):
# Step 1:构造条件输入(当前相机估计)
if pred_pose_enc is None:
module_input = self.embed_pose(self.empty_pose_tokens.expand(B, S, -1))
else:
pred_pose_enc = pred_pose_enc.detach()
module_input = self.embed_pose(pred_pose_enc)
2
3
4
5
- 第 1 轮:没有任何先验,用可学习的
empty_pose_tokens通过embed_pose(Linear 9->2048)映射到 token 空间(全零初始化,形状[1,1,9]广播到[B,S,9],所以每个相机token相同)。 - 后续轮次:把上一轮的 9D 相机预测映射到 token 空间(
detach()切断跨迭代梯度,让每轮独立优化,类似 RAFT 的做法)。
此时 module_input 形状为 [B, S, 2048],代表"当前对相机参数的最优估计"在 token 空间的表达。
# Step 2:生成 AdaLN 调制参数
shift_msa, scale_msa, gate_msa = self.poseLN_modulation(module_input).chunk(3, dim=-1)
poseLN_modulation 是 SiLU -> Linear(2048, 3*2048),把条件输入变成三组参数:
shift_msa [B,S,2048]:对特征做平移scale_msa [B,S,2048]:对特征做缩放gate_msa [B,S,2048]:控制调制后特征的强度
# Step 3:用 AdaLN 调制 pose token
pose_tokens_modulated = gate_msa * modulate(self.adaln_norm(pose_tokens), shift_msa, scale_msa)
pose_tokens_modulated = pose_tokens_modulated + pose_tokens
2
展开来看:
self.adaln_norm(pose_tokens)— 先做 LayerNormmodulate(x, shift, scale)即x * (1 + scale) + shift— 用当前相机估计来自适应地缩放和偏移特征- 再乘
gate_msa— 控制"调制信号"的强度 - 最后加上原始
pose_tokens作为残差连接
第 1 轮时条件接近零向量,调制几乎不生效,trunk 看到的近乎原始 token;后续轮次,条件越来越准,调制越来越有针对性。
# Step 4:通过 Transformer Trunk 提炼
pose_tokens_modulated = self.trunk(pose_tokens_modulated)
self.trunk 是 4 层 Block(标准 Transformer block,含 self-attention + FFN)。输入形状 [B,S,2048],S 个帧之间互相 attend。
这一步让不同帧的相机估计互相参考——比如"如果第 1 帧朝左,第 2 帧应该朝右"这类跨帧几何约束,在这里被隐式建模。
# Step 5:预测增量并累加
pred_pose_enc_delta = self.pose_branch(self.trunk_norm(pose_tokens_modulated))
if pred_pose_enc is None:
pred_pose_enc = pred_pose_enc_delta
else:
pred_pose_enc = pred_pose_enc + pred_pose_enc_delta
2
3
4
5
6
pose_branch 是 MLP(2048 -> 1024 -> 9),把 trunk 输出映射回 9D 相机编码空间。
关键:输出的是pred_pose_enc_delta增量而非绝对值。
网络每次输出的只是"修正量"。
# Step 6:激活并收集
activated_pose = activate_pose(
pred_pose_enc, trans_act=self.trans_act, quat_act=self.quat_act, fl_act=self.fl_act
)
pred_pose_enc_list.append(activated_pose)
2
3
4
对 9D 参数的三个部分分别施加激活:
T[:3]—linear(平移无约束)quat[3:7]—linear(四元数无约束,后续转矩阵时会归一化)FoV[7:9]—relu(视场角必须为正)
每一轮的 activated_pose 都被记录,训练时可以对所有轮次施加监督(deep supervision),推理时取最后一轮。
# DPTHead 结构解析
point_head和depth_head都是DPTHead,只是输出通道数不一样。
DPT(Dense Prediction Transformer)源自论文 "Vision Transformers for Dense Prediction"(Ranftl et al., 2021)。核心思想:从 Transformer 不同深度抽取多尺度特征,用类似 FPN 的逐级融合恢复到像素级分辨率。
VGGT 的 DPTHead 就是在这个框架上做的,但输入不是普通 ViT 特征,而是 Aggregator 产出的跨帧聚合 token。
# 第 1 步:从多层 token 中选 4 层
intermediate_layer_idx: List[int] = [4, 11, 17, 23],
从 Aggregator 的 24 层输出中选第 4、11、17、23 层——分别代表浅层、中层、深层、最深层的特征。每层 token 形状为 [B, S, P, 2C],去掉特殊 token 后只保留 patch token。
# 第 2 步:投影 + reshape 成 2D 特征图
for layer_idx in self.intermediate_layer_idx:
x = aggregated_tokens_list[layer_idx][:, :, patch_start_idx:]
// ...
x = x.reshape(B * S, -1, x.shape[-1])
x = self.norm(x)
x = x.permute(0, 2, 1).reshape((x.shape[0], x.shape[-1], patch_h, patch_w))
x = self.projects[dpt_idx](x)
if self.pos_embed:
x = self._apply_pos_embed(x, W, H)
x = self.resize_layers[dpt_idx](x)
out.append(x)
2
3
4
5
6
7
8
9
10
11
对每层:
- LayerNorm 归一化
- reshape 成
[B*S, 2C, patch_h, patch_w](恢复空间结构) - 1x1 Conv 投影到各自的通道数
[256, 512, 1024, 1024] - 可选加入位置编码(UV 正弦余弦嵌入)
- resize 到不同空间尺度:
- 第 0 层:
ConvTranspose2d stride=4(放大 4x) - 第 1 层:
ConvTranspose2d stride=2(放大 2x) - 第 2 层:
Identity(不变) - 第 3 层:
Conv2d stride=2(缩小 2x)
- 第 0 层:
这样就得到 4 张不同尺度的特征图。
# 第 3 步:自底向上逐级融合(RefineNet 风格)
def scratch_forward(self, features: List[torch.Tensor]) -> torch.Tensor:
layer_1, layer_2, layer_3, layer_4 = features
layer_1_rn = self.scratch.layer1_rn(layer_1)
layer_2_rn = self.scratch.layer2_rn(layer_2)
layer_3_rn = self.scratch.layer3_rn(layer_3)
layer_4_rn = self.scratch.layer4_rn(layer_4)
out = self.scratch.refinenet4(layer_4_rn, size=layer_3_rn.shape[2:])
// ...
out = self.scratch.refinenet3(out, layer_3_rn, size=layer_2_rn.shape[2:])
// ...
out = self.scratch.refinenet2(out, layer_2_rn, size=layer_1_rn.shape[2:])
// ...
out = self.scratch.refinenet1(out, layer_1_rn)
// ...
out = self.scratch.output_conv1(out)
return out
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 先对 4 层各做 3x3 Conv(
layer_rn)统一到 256 通道 - 然后从最深层到最浅层逐级融合:
refinenet4→ 上采样 → 加layer_3→refinenet3→ ... →refinenet1
- 每个
FeatureFusionBlock内部是:
class FeatureFusionBlock(nn.Module):
// ...
def forward(self, *xs, size=None):
output = xs[0]
if self.has_residual:
res = self.resConfUnit1(xs[1])
output = self.skip_add.add(output, res)
output = self.resConfUnit2(output)
// ... bilinear upsample ...
output = self.out_conv(output)
return output
2
3
4
5
6
7
8
9
10
11
即:上一级输出 + 残差卷积处理当前级 → 残差卷积 → 双线性上采样 → 1x1 Conv。
这个过程和 U-Net / FPN 类似,但全部用残差卷积单元(ResidualConvUnit:两层 3x3 Conv + skip connection)。
# 第 4 步:恢复到原始像素分辨率
out = custom_interpolate(
out,
(int(patch_h * self.patch_size / self.down_ratio), int(patch_w * self.patch_size / self.down_ratio)),
mode="bilinear",
align_corners=True,
)
2
3
4
5
6
融合后的特征图再做一次双线性插值,恢复到 H x W(或 H/2 x W/2,取决于 down_ratio)。
# 第 5 步:最终卷积 + 激活分离
out = self.scratch.output_conv2(out)
preds, conf = activate_head(out, activation=self.activation, conf_activation=self.conf_activation)
2
output_conv2:3x3 Conv → ReLU → 1x1 Conv,输出output_dim个通道activate_head把最后一个通道分出来当 置信度,其余通道当预测值:
| 任务头 | output_dim | 预测值 | 激活 | 置信度激活 |
|---|---|---|---|---|
| DepthHead | 2 | 1 通道(深度) | exp(保证正) | 1 + exp(x) |
| PointHead | 4 | 3 通道(xyz) | inv_log(保符号大范围) | 1 + exp(x) |
# 一句话总结
DPTHead = 多层 token 恢复为多尺度 2D 特征图 → 自底向上残差融合(像 FPN)→ 上采样到像素级 → 分离出预测值和置信度。它本质上是把 Transformer 的"扁平 token 序列"重新恢复成"空间金字塔",然后用类 U-Net 的逐级融合做稠密预测。
# TrackHead结构解析
TrackHead 的核心原理是基于特征相关性(Correlation)和时空 Transformer 的迭代式点轨迹细化(Iterative Refinement)。它的设计深受 Co-Tracker 和 VGGSfM 的启发。
简单来说,它的工作流程是:提取稠密特征图 -> 在参考帧采特征 -> 粗略猜测轨迹 -> 局部搜索匹配(算相关性) -> Transformer 预测修正量 -> 循环细化。
其由DPTHead和Tracker模块两个部分组成:
# Feature extractor based on DPT architecture
# Processes tokens into feature maps for tracking
self.feature_extractor = DPTHead(
dim_in=dim_in,
patch_size=patch_size,
features=features,
feature_only=True, # Only output features, no activation
down_ratio=2, # Reduces spatial dimensions by factor of 2
pos_embed=False,
)
# Tracker module that predicts point trajectories
# Takes feature maps and predicts coordinates and visibility
self.tracker = BaseTrackerPredictor(
latent_dim=features, # Match the output_dim of feature extractor
predict_conf=predict_conf,
stride=stride,
corr_levels=corr_levels,
corr_radius=corr_radius,
hidden_size=hidden_size,
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
这里 down_ratio=2 意味着输出的特征图分辨率是原图的一半(例如输入 518x518,特征图就是 259x259),这在保证跟踪精度的同时大幅节省了显存。
推断时先用这个DPTHead提取稠密特征,再用Tracker模块输出最终结果:
def forward(self, aggregated_tokens_list, images, patch_start_idx, query_points=None, iters=None):
"""
Forward pass of the TrackHead.
Args:
aggregated_tokens_list (list): List of aggregated tokens from the backbone.
images (torch.Tensor): Input images of shape (B, S, C, H, W) where:
B = batch size, S = sequence length.
patch_start_idx (int): Starting index for patch tokens.
query_points (torch.Tensor, optional): Initial query points to track.
If None, points are initialized by the tracker.
iters (int, optional): Number of refinement iterations. If None, uses self.iters.
Returns:
tuple:
- coord_preds (torch.Tensor): Predicted coordinates for tracked points.
- vis_scores (torch.Tensor): Visibility scores for tracked points.
- conf_scores (torch.Tensor): Confidence scores for tracked points (if predict_conf=True).
"""
B, S, _, H, W = images.shape
# Extract features from tokens
# feature_maps has shape (B, S, C, H//2, W//2) due to down_ratio=2
feature_maps = self.feature_extractor(aggregated_tokens_list, images, patch_start_idx)
# Use default iterations if not specified
if iters is None:
iters = self.iters
# Perform tracking using the extracted features
coord_preds, vis_scores, conf_scores = self.tracker(query_points=query_points, fmaps=feature_maps, iters=iters)
return coord_preds, vis_scores, conf_scores
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
这个Tracker模块是TrackHead的核心,它的原理来自 CoTracker / RAFT 家族:基于相关性的迭代坐标细化。
结合代码,我们可以把它的原理拆解为以下几个个核心步骤:
# 轨迹初始化 (Initialization)
进入 BaseTrackerPredictor 后,模型需要一个初始的“猜测”。
它直接把第一帧(参考帧)的 query_points 复制到所有帧作为初始坐标,并在第一帧的特征图上“抠”出一个特征来,作为初始的跟踪特征(track_feats)。
def forward(self, query_points, fmaps=None, iters=6, ...):
B, N, D = query_points.shape
B, S, C, HH, WW = fmaps.shape
// ...
query_points = query_points / float(self.stride)
# Init with coords as the query points
coords = query_points.clone().reshape(B, 1, N, 2).repeat(1, S, 1, 1)
# Sample/extract the features of the query points in the query frame
query_track_feat = sample_features4d(fmaps[:, 0], coords[:, 0])
# init track feats by query feats
track_feats = query_track_feat.unsqueeze(1).repeat(1, S, 1, 1) # B, S, N, C
fcorr_fn = CorrBlock(fmaps, num_levels=self.corr_levels, radius=self.corr_radius)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
query_points([B,N,2])是你想要跟踪的像素坐标coords初始化为"所有帧都在 query 坐标位置"——即假设点不动query_track_feat:在第 0 帧(query 帧)采样 query 点的特征,作为"要找什么"track_feats:每个点在每帧的特征表示,初始时 copy query 特征CorrBlock:对特征图构建多尺度金字塔
# 构建相关性金字塔(CorrBlock)
CorrBlock的__init__就是在对 [B,S,C,HH,WW] 的特征图反复做 2x 平均池化放入self.fmaps_pyramid中:
class CorrBlock:
def __init__(self, fmaps, num_levels=4, radius=4, ...):
// ...
self.fmaps_pyramid = [fmaps] # level 0 is full resolution
current_fmaps = fmaps
for i in range(num_levels - 1):
// ...
current_fmaps = F.avg_pool2d(current_fmaps, kernel_size=2, stride=2)
self.fmaps_pyramid.append(current_fmaps)
2
3
4
5
6
7
8
9
这相当于建立了 num_levels 层特征金字塔,越往上分辨率越低但是每个像素包含越大邻近区域的信息。
基于这个特征金字塔,后续操作让 tracker 能同时看到大范围(粗粒度)和精细(细粒度)的匹配信息。
# 迭代细化 (Iterative Refinement)
这是 TrackHead 最核心的机制。模型会循环 iters(默认 4 或 6)次,每次都在当前坐标附近“看一看”,然后预测一个偏移量(Δx,Δy)来修正坐标。
每次迭代有四个关键操作:
for _ in range(iters):
coords = coords.detach()
# ① 相关性采样
fcorrs = fcorr_fn.corr_sample(track_feats, coords)
# ② 位移编码
flows = (coords - coords[:, 0:1]).permute(...)
flows_emb = get_2d_embedding(flows, self.flows_emb_dim, cat_coords=False)
flows_emb = torch.cat([flows_emb, flows / self.max_scale, flows / self.max_scale], dim=-1)
# ③ Update Transformer
transformer_input = torch.cat([flows_emb, fcorrs_, track_feats_], dim=2)
// ...
delta, _ = self.updateformer(x)
# ④ 更新坐标和特征
coords = coords + delta_coords_
track_feats_ = self.ffeat_updater(self.ffeat_norm(delta_feats_)) + track_feats_
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
逐步解释:
# 操作 ①:局部相关性采样 CorrBlock.corr_sample
这个函数在CorrBlock中,基于CorrBlock.__init__中建立的特征金字塔进行操作。
def corr_sample(self, targets, coords):
"""
Instead of storing the entire correlation pyramid, we compute each level's correlation
volume, sample it immediately, then discard it. This saves GPU memory.
Args:
targets: Tensor (B, S, N, C) — features for the current targets.
coords: Tensor (B, S, N, 2) — coordinates at full resolution.
Returns:
Tensor (B, S, N, L) where L = num_levels * (2*radius+1)**2 (concatenated sampled correlations)
"""
B, S, N, C = targets.shape
# If you have multiple track features, split them per level.
if self.multiple_track_feats:
targets_split = torch.split(targets, C // self.num_levels, dim=-1)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
在每一层金字塔上:
out_pyramid = []
for i, fmaps in enumerate(self.fmaps_pyramid):
# Get current spatial resolution H, W for this pyramid level.
B, S, C, H, W = fmaps.shape
2
3
4
先用当前点的 track 特征与该层金字塔上的所有像素的特征计算 dot-product(相关性):
# Reshape feature maps for correlation computation:
# fmap2s: (B, S, C, H*W)
fmap2s = fmaps.view(B, S, C, H * W)
# Choose appropriate target features.
fmap1 = targets_split[i] if self.multiple_track_feats else targets # shape: (B, S, N, C)
# Compute correlation directly
corrs = compute_corr_level(fmap1, fmap2s, C)
corrs = corrs.view(B, S, N, H, W)
2
3
4
5
6
7
8
9
然后在当前预测的 coords 位置,提取周围一个局部窗口(self.radius)内的特征图,与当前的 track_feats 计算内积(相似度):
# Prepare sampling grid:
# Scale down the coordinates for the current level.
centroid_lvl = coords.reshape(B * S * N, 1, 1, 2) / (2**i)
# Make sure our precomputed delta grid is on the same device/dtype.
delta_lvl = self.delta.to(coords.device).to(coords.dtype)
# Now the grid for grid_sample is:
# coords_lvl = centroid_lvl + delta_lvl (broadcasted over grid)
coords_lvl = centroid_lvl + delta_lvl.view(1, 2 * self.radius + 1, 2 * self.radius + 1, 2)
# Sample from the correlation volume using bilinear interpolation.
# We reshape corrs to (B * S * N, 1, H, W) so grid_sample acts over each target.
corrs_sampled = bilinear_sampler(
corrs.reshape(B * S * N, 1, H, W), coords_lvl, padding_mode=self.padding_mode
)
# The sampled output is (B * S * N, 1, 2r+1, 2r+1). Flatten the last two dims.
corrs_sampled = corrs_sampled.view(B, S, N, -1) # Now shape: (B, S, N, (2r+1)^2)
out_pyramid.append(corrs_sampled)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
最后聚合输出:
# Concatenate all levels along the last dimension.
out = torch.cat(out_pyramid, dim=-1).contiguous()
return out
2
3
于是这里的out_pyramid就是当前点的 track 特征在特征金字塔的每一层的当前点附近的self.radius范围内的像素特征的相似度。
输出out_pyramid的形状 [B, S, N, L],对 N 个跟踪点,在 S 帧的每一帧上,在当前预估坐标 coords 周围9x9(self.radius=9)的窗口内,在7层金字塔上分别采样局部相关性值,N=9x9x7=567。
之后的操作就基于该相似度指标确定track点的移动方向和距离。
# 操作 ②:位移编码
计算当前点相对于初始位置移动了多远,并将其编码。
具体来说,其先将输出的fcorrs(out_pyramid)维度进行修改,然后将每个query点的9x9x7的金字塔特征经过一个MLP,把 567 维的原始相关性向量压缩到 128 维:
corr_dim = fcorrs.shape[3] # 567
fcorrs_ = fcorrs.permute(0, 2, 1, 3).reshape(B * N, S, corr_dim) # [B,S,N,567] → [B,N,S,567] → [B*N, S, 567]
fcorrs_ = self.corr_mlp(fcorrs_) # [B*N, S, 567] → [B*N, S, 128]
2
3
这一步MLP压缩提取出"匹配信号的摘要"。 因为原始 567 维太大且冗余(大部分位置不相关),MLP 学习从中提取有用的匹配模式。
然后把"当前帧坐标相对于 query 帧的偏移量"编码成正弦余弦 embedding,再拼上归一化后的原始位移值:
# Movement of current coords relative to query points
flows = (coords - coords[:, 0:1]).permute(0, 2, 1, 3).reshape(B * N, S, 2)
flows_emb = get_2d_embedding(flows, self.flows_emb_dim, cat_coords=False)
# (In my trials, it is also okay to just add the flows_emb instead of concat)
flows_emb = torch.cat([flows_emb, flows / self.max_scale, flows / self.max_scale], dim=-1)
2
3
4
5
6
7
coords[:, 0:1]是要 track 的像素在第一帧的坐标,和coords相减得到每一帧track到的坐标相对于第一帧的位移。
get_2d_embedding把 2D 位移 (dx, dy) 用正弦/余弦编码到高维空间,和 Transformer 的位置编码原理一样——让网络能区分不同尺度的位移(小偏移 vs 大偏移):
def get_2d_embedding(xy: torch.Tensor, C: int, cat_coords: bool = True) -> torch.Tensor:
"""
This function generates a 2D positional embedding from given coordinates using sine and cosine functions.
Args:
- xy: The coordinates to generate the embedding from.
- C: The size of the embedding.
- cat_coords: A flag to indicate whether to concatenate the original coordinates to the embedding.
Returns:
- pe: The generated 2D positional embedding.
"""
B, N, D = xy.shape
assert D == 2
x = xy[:, :, 0:1]
y = xy[:, :, 1:2]
div_term = (torch.arange(0, C, 2, device=xy.device, dtype=torch.float32) * (1000.0 / C)).reshape(1, 1, int(C / 2))
pe_x = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
pe_y = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
pe_x[:, :, 0::2] = torch.sin(x * div_term)
pe_x[:, :, 1::2] = torch.cos(x * div_term)
pe_y[:, :, 0::2] = torch.sin(y * div_term)
pe_y[:, :, 1::2] = torch.cos(y * div_term)
pe = torch.cat([pe_x, pe_y], dim=2) # (B, N, C*3)
if cat_coords:
pe = torch.cat([xy, pe], dim=2) # (B, N, C*3+3)
return pe
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
这是用transformer能听懂的语言告诉"这个点已经偏移了多远"。
# 操作 ③:Update Transformer
把运动信息 (flows_emb)、局部匹配度 (fcorrs_) 和 当前特征 (track_feats_) 拼接起来:
# Concatenate them as the input for the transformers
transformer_input = torch.cat([flows_emb, fcorrs_, track_feats_], dim=2)
2
获取位置编码:
# 2D positional embed
# TODO: this can be much simplified
pos_embed = get_2d_sincos_pos_embed(self.transformer_dim, grid_size=(HH, WW)).to(query_points.device)
sampled_pos_emb = sample_features4d(pos_embed.expand(B, -1, -1, -1), coords[:, 0])
sampled_pos_emb = rearrange(sampled_pos_emb, "b n c -> (b n) c").unsqueeze(1)
2
3
4
5
6
其中get_2d_sincos_pos_embed计算整张图的位置编码,sample_features4d根据待track的点在第一帧上的位置coords[:, 0]获取位置编码。
相当于用transformer能听懂的语言告诉"这个点从哪出发"。
相加后送入 EfficientUpdateFormer:
x = transformer_input + sampled_pos_emb
# Add the query ref token to the track feats
query_ref_token = torch.cat(
[self.query_ref_token[:, 0:1], self.query_ref_token[:, 1:2].expand(-1, S - 1, -1)], dim=1
)
x = x + query_ref_token.to(x.device).to(x.dtype)
# B, N, S, C
x = rearrange(x, "(b n) s d -> b n s d", b=B)
# Compute the delta coordinates and delta track features
delta, _ = self.updateformer(x)
2
3
4
5
6
7
8
9
10
11
12
13
这个 Transformer 会在时间(帧与帧之间)和空间(点与点之间)计算Attention,从而输出坐标的修正量 delta_coords 和特征的修正量 delta_feats:
class EfficientUpdateFormer(nn.Module):
// ...
def forward(self, input_tensor, mask=None):
tokens = self.input_transform(input_tensor) # B, N, S, hidden
// ...
for i in range(len(self.time_blocks)):
# Time attention: each point independently attend across frames
time_tokens = tokens.view(B * N, T, -1)
time_tokens = self.time_blocks[i](time_tokens)
# Space attention (every few layers): points interact within each frame
if self.add_space_attn and ...:
space_tokens = tokens.permute(0,2,1,3).view(B*T, N, -1)
# virtual tokens act as communication bottleneck
virtual_tokens = self.space_virtual2point_blocks[j](virtual_tokens, point_tokens)
virtual_tokens = self.space_virtual_blocks[j](virtual_tokens)
point_tokens = self.space_point2virtual_blocks[j](point_tokens, virtual_tokens)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
两种注意力交替:
- Time Attention:把每个点的 S 帧 token 当一条序列做自注意力。让同一个点在不同帧之间交流,理解"这个点的时间轨迹应该是怎样的"
- Space Attention:把同一帧中所有 N 个点当一条序列做注意力。让同帧的不同点互相交流(比如可能会学习到利用"刚性运动约束"——如果周围点都往右移,那我大概也该往右)。
空间注意力用了 虚拟 token 瓶颈(64 个 virtual tracks)来避免 O(N^2) 的开销:先 point→virtual(cross-attn),再 virtual self-attn,最后 virtual→point(cross-attn)。
输出:每个点每帧的 delta(坐标增量 + 特征增量)。
# 操作 ④:更新
将算出的坐标delta加到当前的坐标上、特征delta经过一个ffeat_updater加到特征上:
# Update the track features
track_feats_ = self.ffeat_updater(self.ffeat_norm(delta_feats_)) + track_feats_
track_feats = track_feats_.reshape(B, N, S, self.latent_dim).permute(0, 2, 1, 3) # BxSxNxC
# B x S x N x 2
coords = coords + delta_coords_.reshape(B, N, S, 2).permute(0, 2, 1, 3)
# Force coord0 as query
# because we assume the query points should not be changed
coords[:, 0] = coords_backup[:, 0]
2
3
4
5
6
7
8
9
10
11
注意,第一帧(参考帧)的坐标被强制重置为初始值,因为它是不应该变的。
# 预测可见性与置信度 (Visibility & Confidence)
在所有迭代结束后,点在每一帧的最终特征 track_feats 已经融合了时空信息。模型直接用两个简单的线性层(Linear + Sigmoid)来判断这个点在当前帧是否可见(比如被遮挡、移出画面),以及预测的置信度。
# B, S, N
vis_e = self.vis_predictor(track_feats.reshape(B * S * N, self.latent_dim)).reshape(B, S, N)
if apply_sigmoid:
vis_e = torch.sigmoid(vis_e)
if self.predict_conf:
conf_e = self.conf_predictor(track_feats.reshape(B * S * N, self.latent_dim)).reshape(B, S, N)
if apply_sigmoid:
conf_e = torch.sigmoid(conf_e)
2
3
4
5
6
7
8
9
# 总结
TrackHead 放弃了传统光流那种一次性回归整张图位移的做法,而是采用了**稀疏点追踪(Sparse Point Tracking)**的范式: 先提特征 -> 猜个位置 -> 看看周围像不像 -> Transformer 综合上下文给出修正建议 -> 挪动位置 -> 再看周围像不像... 如此循环。 这种方法对长视频、大位移和遮挡具有极强的鲁棒性。