博弈论
# Normal form game
形式化定义一个可终止(Finite)的、有n个主体参与的博弈为:
⟨N,A,u⟩
其中,
- Players:N={1,…,i,…,n}表示参与博弈的主体
- Actions:Ai表示Player i可以采取的动作集合,定义Action Profile为a=(a1,…,an)∈A=A1×⋯×An,表示一个可能出现的情况
- Payoff function(Utility function, 效用函数):ui:A↦R表示Player i的Payoff function,用来计算特定Action Profile下Player i可以获取的回报;u=(u1,…,ui,…,un)表示profile of utility function
# 最佳响应 Best Response
令a−i=⟨a1,…,ai−1,ai+1,…,an⟩表示除Player i外的其他所有Player选择的Actions,并将包含Player i在内的所有Player选择的Actions记为a=(a−i,ai)
对于某已知的a−i,其最佳响应集BR(a−i)定义为:
BR(a−i)={ai∗∣∀ai∈Ai,ui(ai∗,a−i)≥ui(ai,a−i)}
即在已知所有其他Player选择的Actiona−i的情况下给Player i带来最大效用的ai的集合
# 纳什均衡 Nash Equilibrium
Pure Strategy 纳什均衡a=⟨a1,…,ai,…,an⟩定义为:
∀i∈[1,n],ai∈BR(a−i)
即每个Player的Action均为Best Response的Action Profile
# 优势策略 dominant strategy
令S−i={a−i}表示除Player i外的其他所有Player所有可能Action的集合
策略si严格优于(strictly dominates)si′定义为
∀s−i∈S−i,ui(si,s−i)>ui(si′,s−i)
策略si弱优于(very weakly dominates)si′定义为
∀s−i∈S−i,ui(si,s−i)≥ui(si′,s−i)
严格优于所有其他策略的策略称为优势策略
# 帕累托最优 Pareto Optimality
多目标优化问题的数学模型一般可以写成如下形式:
mins.t.f(x)={f1(x),f2(x),…,fn(x)}x∈XX⊆Rm
其中,f1(x),f2(x),…,fn(x)表示n个目标函数,X⊆Rm是其变量约束的集合。
# 定义:解A强帕累托支配解B
假设现在有两个目标函数,解A对应的目标函数值都比解B对应的目标函数值好,则称解A比解B优越,也可以叫做解A强帕累托支配解B
# 定义:解A能帕累托支配解B
同样假设两个目标函数,解A对应的一个目标函数值优于解B对应的一个目标函数值,但是解A对应的另一个目标函数值要差于解B对应的一个目标函数值,则称解A无差别于解B,也叫作解A能帕累托支配解B
# 定义:最优解
假设在设计空间中,解A对应的所有目标函数值都达到最优,则称解A为最优解

必须有一个点让所有函数同时最优,条件很苛刻,基本不可能
# 定义:帕累托最优解
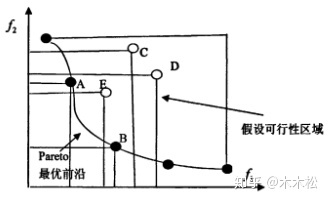
假设两个目标函数,对于解A而言,在 变量空间 中找不到其他的解能够强帕累托支配解A,那么解A就是帕累托最优解(在其他任何解上都有一些目标函数值比解A差)(通常是一个范围)

比如上图这样的帕累托最优就是一个范围[x1,x2]
# 定义:帕累托最优前沿
帕累托最优解组成的集合
# Mixed strategy
Mixed strategy是Action的概率分布。不同于Pure strategy中的策略ai定义为Playeri从策略集Ai中选择的某个Action,Mixed strategy中的策略si定义为Playeri在策略集Ai上的概率分布。
定义si为Playeri在策略集Ai上的概率分布,si(ai)为Playeri选择策略ai的概率,令a−i=⟨a1,…,ai−1,ai+1,…,an⟩表示除Player i外的其他所有Player选择的Actions,并将包含Player i在内的所有Player选择的Actions记为a=(a−i,ai)。那么,Mixed strategy下的纳什均衡s=⟨s1,…,si,…,sn⟩定义为:
∀i∈N,∀ai∈Aia∑ui(a)j∈N∏sj(aj)≥a−i∑ui(a−i,ai)j∈N,j=i∏sj(aj)
很显然,不等式左边的ui(a)表示某个Action组合a给Playeri带来的效用,∏j∈Nsj(aj)是a中的Action aj在Mixed strategy策略sj中的概率,所以很显然这一项是Action组合a在Mixed strategy策略sj下发生的概率,所以整个∑aui(a)∏j∈Nsj(aj)这一项就表示所有Player的Mixed strategy策略给Playeri带来的效用值的数学期望。
而不等式右边的的项很显然就是Playeri确定选某个ai的情况下(si(ai)=1)的Mixed strategy策略给Playeri带来的效用值的数学期望。
所以用人话将,Mixed strategy下的纳什均衡就是:所有Playeri确定选择任何一个策略ai都不如Mixed strategy策略si能带来更大的效用期望值。