原文在此
摘要
高斯分布被誉为"上帝的分布", 其强悍的建模能力和优美的数学性质使得高斯分布在现实中得到广泛的应用. 由中心极限定理 [1] 我们知道, 大量独立同分布的随机变量的均值在做适当标准化之后会依分布收敛于高斯分布, 这使得高斯分布具有普适性的建模能力. 数学上, 当使用高斯分布对贝叶斯推断的似然和先验进行建模时, 得到的后验同样为高斯分布, 即其具有共轭先验性质. 在随机过程理论中, 多元高斯分布则是高斯过程的理论基础. 这种种场景使得高斯分布颇受重视, 并发展出一套成熟完整的理论体系. 本文主要介绍多元高斯分布的由来与其背后的几何原理, 分为如下章节:
- 阐述多元标准高斯分布;
- 由多元标准高斯分布导出多元高斯分布;
- 阐述多元高斯分布的几何意义;
- 总结.
关键词: 多元高斯分布, 高斯过程, 概率论与数理统计, 机器学习
校对: @叶定南, @Towser, @Syous
多元标准高斯分布
熟悉一元高斯分布的同学都知道, 若随机变量 X∼N(μ,σ2) , 则有如下的概率密度函数
p(x)=σ2π1⋅e−21⋅(σx−μ)2(1)
1=∫−∞+∞p(x)dx(2)
而如果我们对随机变量 X 进行标准化, 用 Z=σX−μ 对(1)进行换元, 继而有
∵x(z)∴p(x(z))1=z⋅σ+μ=σ2π1⋅e−21⋅(z)2=∫−∞+∞p(x(z))dx=∫−∞+∞σ2π1⋅e−21⋅(z)2dx=∫−∞+∞2π1⋅e−21⋅(z)2dz(3)
此时我们说随机变量 Z∼N(0,1) 服从一元标准高斯分布, 其均值 μ=0 , 方差 σ2=1 , 其概率密度函数为
p(z)=2π1⋅e−21⋅(z)2(4)
需要注意的是, 为了保证概率密度函数在 R 上的积分为1, 换元时需要求 dx=σ⋅dz , 从而得到(3).
随机变量 X 标准化的过程, 实际上的消除量纲影响和分布差异的过程. 通过将随机变量的值减去其均值再除以标准差, 使得随机变量与其均值的差距可以用若干个标准差来衡量, 从而实现了不同随机变量与其对应均值的差距, 可以以一种相对的距离来进行比较.
一元标准高斯分布与我们讨论多元标准高斯分布有什么关系呢? 事实上, 多元标准高斯分布的概率密度函数正是从(4)导出的. 假设我们有随机向量 Z=[Z1,⋯,Zn]⊤ , 其中 Zi∼N(0,1)(i=1,⋯,n) 且 Zi,Zj(i,j=1,⋯,n∧i=j) 彼此独立, 即随机向量中的每个随机变量 Zi 都服从标准高斯分布且两两彼此独立. 则由(4)与独立随机变量概率密度函数之间的关系, 我们可得随机向量 Z=[Z1,⋯,Zn]⊤ 的联合概率密度函数为
p(z1,⋯,zn)1=i=1∏n2π1⋅e−21⋅(zi)2=(2π)2n1⋅e−21⋅(Z⊤Z)=∫−∞+∞⋯∫−∞+∞p(z1,⋯,zn)dz1⋯dzn(5)
我们称随机向量 Z∼N(0,I) , 即随机向量服从均值为零向量, 协方差矩阵为单位矩阵的高斯分布. 在这里, 随机向量 Z 的协方差矩阵是 Conv(Zi,Zj),i,j=1,⋯,n 组成的矩阵, 即
[Conv(Zi,Zj)]n×n=E[(Z−μ)(Z−μ)⊤]=I(6)
由于随机向量 Z∼N(0,I) , 所以其协方差矩阵的对角线元素为1, 其余元素为0. 如果我们取常数 c=p(z1,⋯,zn) , 则可得函数 p(z1,⋯,zn) 的等高线为 c′=Z⊤Z , 当随机向量 Z 为二维向量时, 我们有
c′=Z⊤⋅Z=(z1−0)2+(z2−0)2(7)
由(7)我们可知, 其等高线为以(0, 0)为圆心的同心圆.
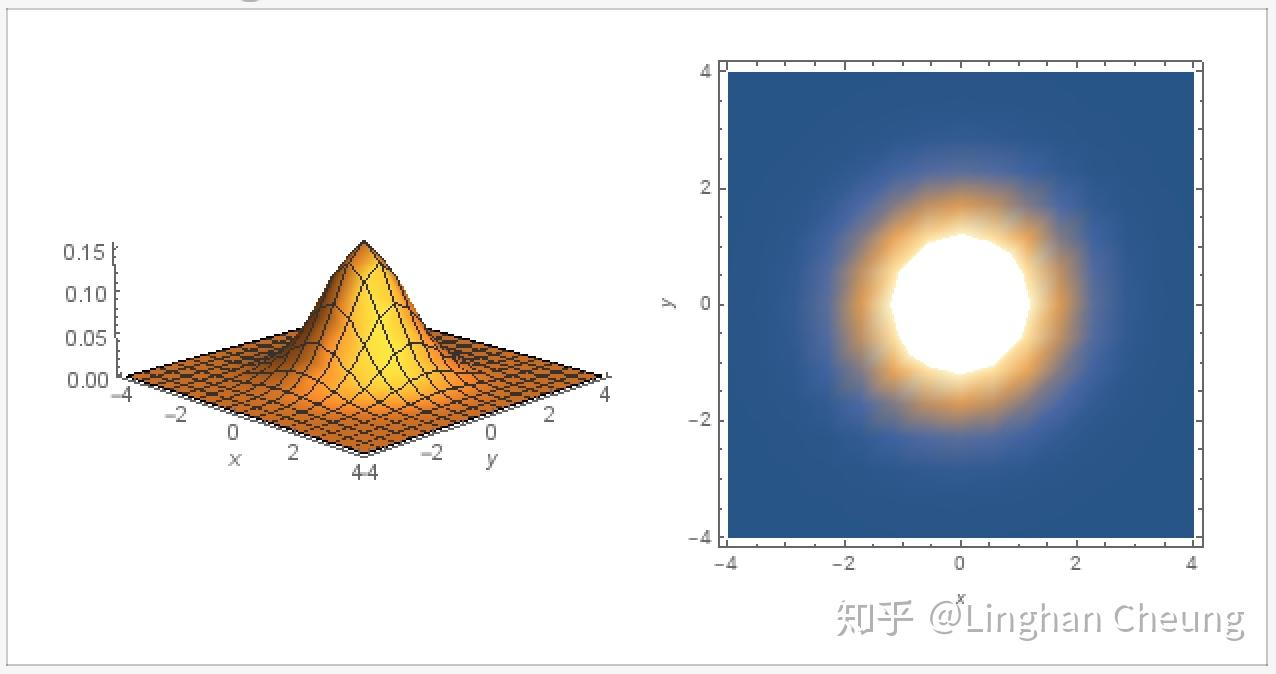
多元高斯分布
由上一节我们知道, 当随机向量 Z∼N(0,I) 时, 其每个随机变量 Zi∼N(0,1)(i=1,⋯,n) 彼此独立, 我们可通过(4)与独立随机变量概率密度函数之间的关系得出其联合概率密度函数(5). 那对于普通的随机向量 X∼N(μ,Σ) , 即其每个随机变量 Xi∼N(μi,σi2)(i=1,⋯,n) 且 Xi,Xj(i,j=1,⋯,n) 彼此不独立的情况下, 我们该如何求随机向量 X 的联合概率密度函数呢? 一个很自然的想法是, 如果我们能通过线性变换, 使得随机向量 X=[X1,⋯,Xn]⊤ 中的每个随机变量彼此独立, 则我们也可以通过独立随机变量概率密度函数之间的关系求出其联合概率密度函数 . 事实上, 我们有如下定理可完成这个工作 [2]
定理1: 若存在随机向量 X∼N(μ,Σ) , 其中 μ∈Rn 为均值向量, Σ∈S++n×n 半正定实对称矩阵为 X 的协方差矩阵, 则存在满秩矩阵 B∈Rn×n , 使得 Z=B−1(X−μ) , 而 Z∼N(0,I) .
有了定理1, 我们就可以对随机向量 X 做相应的线性变换, 使其随机变量在线性变换后彼此独立, 从而求出其联合概率密度函数, 具体地
∵∴Zp(z1,⋯,zn)p(z1(x1,⋯,xn),⋯)=B−1(X−μ),Z∼N(0,I)=(2π)2n1⋅e−21⋅(Z⊤Z)=(2π)2n1⋅e−21⋅[(B−1(X−μ))⊤(B−1(X−μ))]=(2π)2n1⋅e−21⋅[(X−μ)⊤(BB⊤)−1(X−μ)](8)
∴1=∫−∞+∞=∫−∞+∞⋯∫−∞+∞p(z1(x1,⋯,xn),⋯)dz1⋯dzn⋯∫−∞+∞(2π)2n1⋅e−21⋅[(X−μ)⊤(BB⊤)−1(X−μ)]dz1⋯dzn(9)
由多元函数换元变换公式, 我们还需要求出雅可比行列式 J(Z→X) , 由(8)可得
J(Z→X)=∣∣∣B−1∣∣∣=∣B∣−1=∣B∣−21⋅∣∣∣B⊤∣∣∣−21=∣∣∣BB⊤∣∣∣−21(10)
由(9)(10), 我们可进一步得
1=∫−∞+∞⋯∫−∞+∞(2π)2n∣BB⊤∣211⋅e−21⋅[(X−μ)⊤(BB⊤)−1(X−μ)]dx1⋯dxn(11)
我们得到随机向量 X∼N(μ,Σ) 的联合概率密度函数为
p(x1,⋯,xn)=(2π)2n∣BB⊤∣211⋅e−21⋅[(X−μ)⊤(BB⊤)−1(X−μ)](12)
在(12)中, 随机向量 X 的协方差矩阵还未得到体现, 我们可通过线性变换(8)做进一步处理
Σ=E[(X−μ)(X−μ)⊤]=E[(BZ−0)(BZ−0)⊤]=Conv(BZ,BZ)=BConv(Z,Z)B⊤=BB⊤(13)
我们发现, (12)中 BB⊤ 就是线性变换前的随机向量 X∼N(μ,Σ) 的协方差矩阵 Σ , 所以由(12)(13), 我们可以得到联合概率密度函数的最终形式
p(x1,⋯,xn)=(2π)2n∣Σ∣211⋅e−21⋅[(X−μ)⊤Σ−1(X−μ)](14)
原本由定理1, 我们还需要求线性变换矩阵 B , 才能确定随机向量 X 的联合概率密度函数的表达式, 现在由(13)我们即可得最终形式(14), 随机向量 X 的联合概率密度函数由其均值向量 μ 和其协方差矩阵 Σ 唯一确定, 但我们需要明白的是, 这是通过定理1的线性变换 Z=B−1(X−μ) 得到的, 即此线性变换隐含其中.
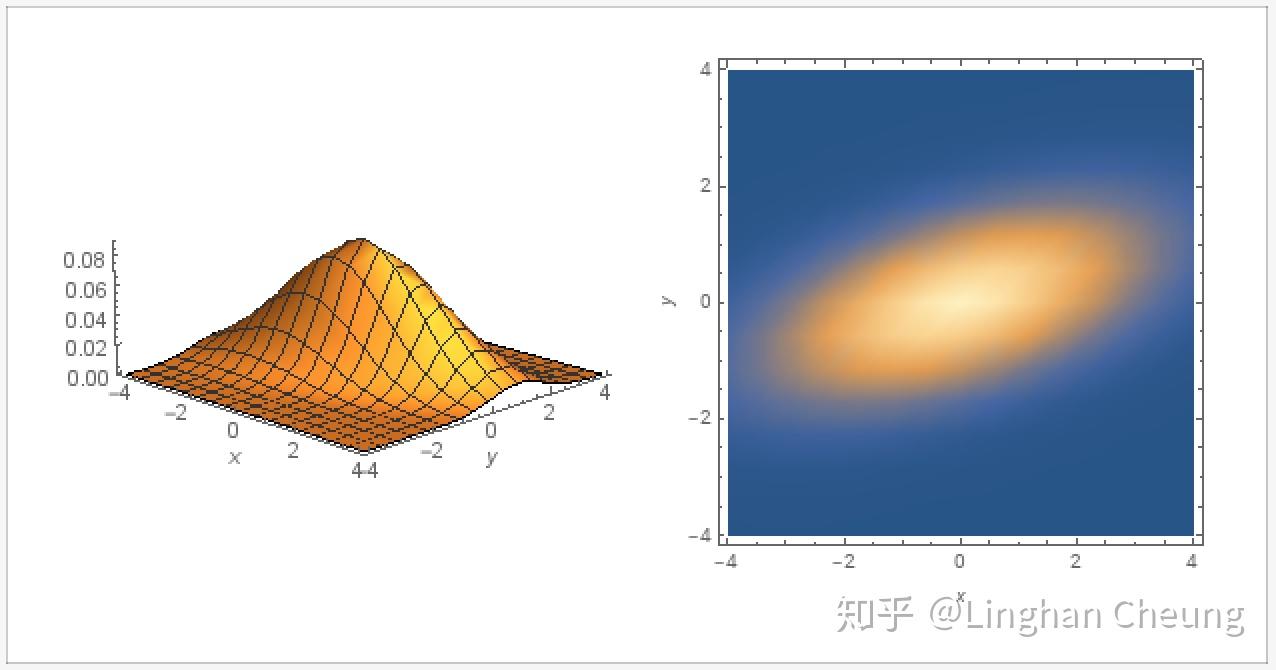
如果我们取常数 c=p(x1,⋯,xn) , 则可得函数 p(x1,⋯,xn) 的等高线为 c′=(X−μ)⊤Σ−1(X−μ) , 当随机向量 X 为二维向量时, 我们对协方差矩阵 Σ 进行分解, 因为其为实对称矩阵, 可正交对角化
Σc′=QΛQ⊤=(X−μ)⊤(QΛQ⊤)−1(X−μ)=(X−μ)⊤QΛ−1Q⊤(X−μ)=[Q⊤(X−μ)]⊤Λ−1[Q⊤(X−μ)](15)
由于矩阵 Q 是酉矩阵, 所以 Q⊤(X−μ)=Q⊤X−Q⊤u 可以理解为将随机向量 X , 均值向量 μ 在矩阵 Q 的列向量所组成的单位正交基上进行投影并在该单位正交基上进行相减. 我们不妨记投影后的向量分别为 XQ=Q⊤X,uQ=Q⊤μ , 同时记矩阵 Λ=[λ100λ2],λ1≥λ2 , 则(15)的二次型可表示为
c′=(λ1XQ1−μQ1)2+(λ2XQ2−μQ2)2(16)
由(16)我们可知, 此时函数 p(x1,⋯,xn) 的等高线是在矩阵 Q 的列向量所组成的单位正交基上的一个椭圆, 椭圆的中心是 uQ=[μQ1,μQ2]⊤ , 长半轴为 λ1 , 短半轴为 λ2 .
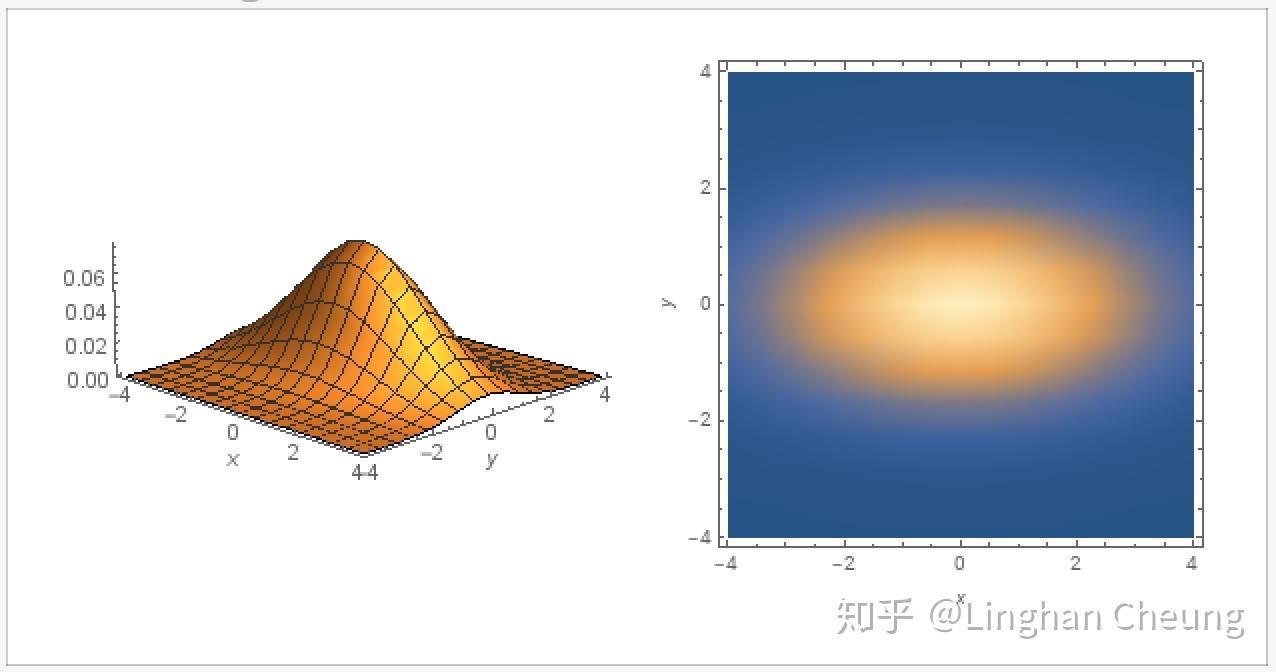
如果协方差矩阵 Σ 不是对角矩阵, 则正交对角化得到的酉矩阵 Q 不是标准正交基, 其代表一个旋转, 此时的椭圆应该是一个倾斜的椭圆, 随机向量 X 中的随机变量不是彼此独立的;
如果协方差矩阵 Σ 是对角矩阵, 则正交对角化得到的酉矩阵 Q 就是标准正交基, 则前述的投影是在标准正交基上完成的, 此时的椭圆应该是一个水平的椭圆, 随机向量 X 中的随机变量就是彼此独立的.
多元高斯分布的几何意义
现在我们知道, 随机向量 X∼N(μ,Σ) 的联合概率密度函数是通过线性变换 Z=B−1(X−μ) 的帮助, 将随机向量 X 的各个随机变量去相关性, 然后利用独立随机变量概率密度函数之间的关系得出的, 亦既是定理1所表述的内容. 那具体地, 线性变化 Z=B−1(X−μ) 是怎么去相关性使随机向量 X 的各个随机变量彼此独立的呢? 我们不妨在二维平面上, 再次由定理1和(15)出发来看看这个去相关性的过程.
由定理1我们有
∵∴ZZ⊤Z=B−1(X−μ),Z∼N(0,I)=(B−1(X−μ))⊤(B−1(X−μ))=(X−μ)⊤(BB⊤)−1(X−μ)=(X−μ)⊤Σ−1(X−μ)(17)
再由(15)(17)可得
Z⊤Z=[Q⊤(X−μ)]⊤Λ−1[Q⊤(X−μ)]=[Q⊤(X−μ)]⊤(Λ−21)⊤Λ−21[Q⊤(X−μ)]=[Λ−21Q⊤(X−μ)]⊤[Λ−21Q⊤(X−μ)]=[(QΛ−21)⊤(X−μ)]⊤[(QΛ−21)⊤(X−μ)]=[(Q⋅[λ1100λ21])⊤(X−μ)]⊤⋅[(Q⋅[λ1100λ21])⊤(X−μ)](18)
由(18)我们已经可以非常明显地看出线性变换 Z=B−1(X−μ) 的具体操作了
将随机向量X去均值后在新正交基上投影(对拉伸后的正交基旋转Q⋅对标准正交基拉伸[λ1100λ21])⊤(X−μ)(19)
我们先对标准正交基进行拉伸, 横轴和纵轴分别拉伸 λ11,λ21 倍, 再使用酉矩阵 Q 对拉伸后的正交基进行旋转, 最后将去均值的随机向量 X−μ 在新的正交基上进行投影, 从而使完成线性变换 Z=B−1(X−μ) 后的随机变量在新的正交基上彼此独立. 值得注意的是, 如果随机向量 X 本来就是独立随机变量组成的, 此时其协方差矩阵是一个对角矩阵, 则酉矩阵 Q 是一个单位矩阵 I , 此线性变换中只有拉伸而没有旋转.
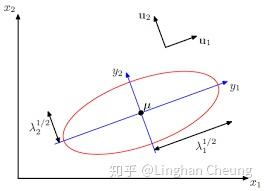
而如果我们只保留 (QΛ−21)⊤(X−μ) 这个投影后坐标轴长度较长的对应的坐标, 我们就可以达到将随机向量 X 进行降维的效果, 而这, 就是所谓的PCA(principal component analysis, 主成分分析).
总结
本文从多元标准高斯分布出发, 阐述了如何通过线性变换, 将任意的服从多元高斯分布的随机向量去相关性, 并求出其联合概率密度函数的过程, 最后给出了线性变换的具体过程阐述. 多元高斯分布是许多其他理论工具的基础, 掌握它是进行其他相关理论研究的关键.
引用
[1] Wikipedia contributors. "中心极限定理."维基百科, 自由的百科全书. 维基百科, 自由的百科全书, 9 May 2018. Web. 9 May 2018.‹https://zh.wikipedia.org/w/index.php?title=%E4%B8%AD%E5%BF%83%E6%9E%81%E9%99%90%E5%AE%9A%E7%90%86&oldid=49494817›.
[2] Do, C. (2008).The Multivariate Gaussian Distribution. [online] Cs229.stanford.edu. Available at: http://cs229.stanford.edu/section/gaussians.pdf [Accessed 13 Mar. 2019].
[3] 张, 伟. (2019). 多元正态分布. [online] Staff.ustc.edu.cn. Available at: http://staff.ustc.edu.cn/~zwp/teach/MVA/Lec4_slides.pdf [Accessed 13 Mar. 2019].
[4] Wikipedia contributors. "多元正态分布."维基百科, 自由的百科全书. 维基百科, 自由的百科全书, 16 Sep. 2018. Web. 16 Sep. 2018.‹https://zh.wikipedia.org/w/index.php?title=%E5%A4%9A%E5%85%83%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83&oldid=51304757›.
[5] Wikipedia contributors. "雅可比矩阵."维基百科, 自由的百科全书. 维基百科, 自由的百科全书, 7 Dec. 2018. Web. 7 Dec. 2018.‹https://zh.wikipedia.org/w/index.php?title=%E9%9B%85%E5%8F%AF%E6%AF%94%E7%9F%A9%E9%98%B5&oldid=52294204›.