Deep Unfolding Network for Image Super-Resolution
@inproceedings{DeepUnfoldingNetworkImage2020,
title = {Deep {{Unfolding Network}} for {{Image Super}}-{{Resolution}}},
booktitle = {2020 {{IEEE}}/{{CVF Conference}} on {{Computer Vision}} and {{Pattern Recognition}} ({{CVPR}})},
author = {Zhang, Kai and Van Gool, Luc and Timofte, Radu},
date = {2020-06},
pages = {3214--3223},
publisher = {{IEEE}},
location = {{Seattle, WA, USA}},
doi = {10.1109/CVPR42600.2020.00328},
url = {https://ieeexplore.ieee.org/document/9157092/},
urldate = {2021-05-14},
archiveprefix = {arXiv},
eprint = {2003.10428},
eprinttype = {arxiv},
eventtitle = {2020 {{IEEE}}/{{CVF Conference}} on {{Computer Vision}} and {{Pattern Recognition}} ({{CVPR}})},
isbn = {978-1-72817-168-5},
keywords = {Computer Science - Computer Vision and Pattern Recognition,Electrical Engineering and Systems Science - Image and Video Processing},
langid = {english}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 概括
# 研究现状
- 基于模型的方法:基于图像降质的光学模型对图像进行超分辨率
- 不需要训练,也没有超参数
- 能适应不同的缩放尺度、模糊核和噪声
- 可解释性好
- 基于机器学习的方法:使用机器学习中的一些方法对图像进行超分辨率
- 需要大量数据进行训练
- 训练数据决定了适用范围,单一个模型无法适应多种不同的缩放尺度、模糊核和噪声
- 效果比基于模型的方法好
# 本文贡献
结合基于模型的方法和基于机器学习的方法进行超分辨率
# 本文使用的基于模型的方法:Deep Unfolding
Deep Unfolding 是前人已有的研究,是一种基于光学模型的迭代求解方法
参考论文:《Learning Deep CNN Denoiser Prior for Image Restoration》
# 图像降质的光学模型
y=(x⊗k)↓s+n
- (x⊗k):原始高清图像x与一个模糊核k卷积
- ↓s:进行s×s下采样(其实就是池化)
- n:噪声
# MAP(最大后验概率) framework 估计高清图
已知模糊核k,使E(x)最小的高清图像x就是最大后验概率估计得到的高清图
E(x)=2σ21∥y−(x⊗k)↓s∥2+λΦ(x)
- 2σ21∥y−(x⊗k)↓s∥2:保真项
- λΦ(x):用于处理噪声的惩罚项,λ为trade-off参数
# 半二次分裂(half-quadratic spliting, HQS)算法
原问题:
minxf(x)+g(x)
半二次分裂近似问题:
minx,zs.t.f(x)+g(z)x=z
增广拉格朗日:
L(x,z;μ)=f(x)+g(z)+2μ∥x−z∥2
半二次分裂迭代求解:
⎩⎪⎪⎨⎪⎪⎧zk+1xk+1=argminzf(xk)+g(z)+2μ∥xk−z∥2=argminxf(x)+g(zk)+2μ∥x−zk∥2
固定x优化z、固定z优化x,如此循环往复逼近最优解。
# MAP framework + HQS = Deep Unfolding
原问题:
minxE(x)=2σ21∥y−(x⊗k)↓s∥2+λΦ(x)
半二次分裂近似+增广拉格朗日:
L(x,z;μ)=2σ21∥y−(z⊗k)↓s∥2+λΦ(x)+2μ∥z−x∥2
迭代:
⎩⎪⎨⎪⎧zkxk=argminz∥y−(z⊗k)↓s∥2+μσ2∥z−xk−1∥2=argminxλΦ(x)+2μ∥zk−x∥2
μ should be large enough so that x and z are approximately equal to the fixed point. However, this would also result in slow convergence. Therefore, a good rule of thumb is to iteratively increase µ. For convenience, the μ in the k-th iteration is denoted by μk.
# Deep Unfolding + 机器学习
核心思想就是把上面的两个迭代求解式看成由两层神经网络组成的一个模块,把迭代的过程看成是网络模块的堆叠。这种将迭代做成堆叠的方法也是model-based问题用learning-based框架来解决的常见方法。
两个迭代求解式分别变成两层神经网络:
- Data Module:zk=D(xk−1,s,k,y,αk)
- Prior Module:xk=P(zk,βk)
堆叠:
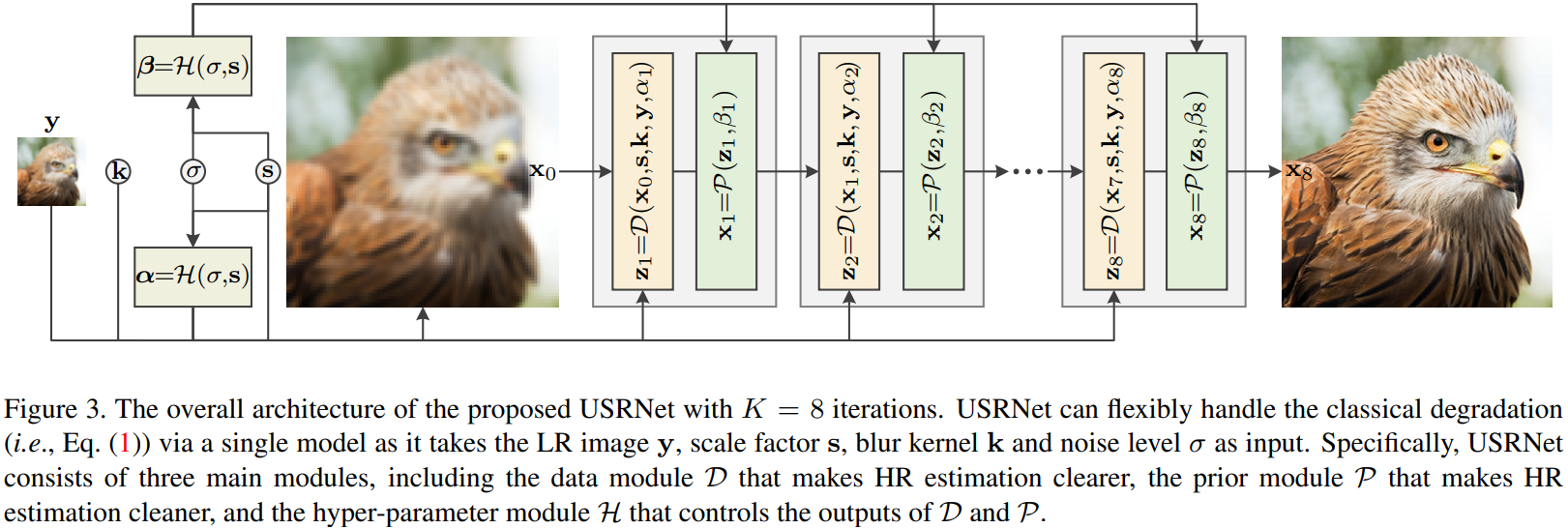
# 估计模糊核k
根据前面介绍的图像降质的光学模型y=(x⊗k)↓s+n,恢复图像时所用到的模糊核k可以直接用一些简单的估计方法得到:
kbicubic×s=argmink∥(x⊗k)↓s−y∥
# Data Module
Data Module 就是求解迭代方程中的zk:
zk=argminz∥y−(z⊗k)↓s∥2+μσ2∥z−xk−1∥2
这个式子归根到底就是一个复杂的一元二次方程,作者把它转到频域里解:
zk=D(xk−1,s,k,y,αk)=F−1(αk1(d−F(k)⊙s(F(k)F(k))⇓s+αk(F(k)d)⇓s))
其中:
d=F(k)F(y↑s)+αkF(xk−1)
αk=μkσ2
- F(⋅)、F−1(⋅)、F(⋅):傅里叶变换、傅里叶反变换、傅里叶变换的共轭复数
- ⊙s:the distinct block processing operator with element-wise multiplication, i.e., applying elementwise multiplication to the s×s distinct blocks of F(k)
- ⇓s:the distinct block downsampler, i.e., averaging the s×s distinct blocks
- ↑sthe standard s-fold upsampler, i.e., upsampling the spatial size by filling the new entries with zeros
于是,D(xk−1,s,k,y,αk)就是Data Module,这里面没有任何需要学习的参数
# Prior Module
在图像领域,xk=argminxλΦ(x)+2μ∥zk−x∥2是典型的图像去噪问题,noise level βk=λ/μk。
作者就是在这里用了一个CNN网络来完成降噪的任务。网络的输入是zk,输出是xk
CN网络的结构是ResNet+U-Net。 U-Net is widely used for image-to-image mapping, while ResNet owes its popularity to fast training and its large capacity with many residual blocks.
# 超参数 Module
至此,还有没能确定的参数是αk=μkσ2和βk=λ/μk,其中σ是数据集整体的特征,要通过统计方法提前知晓,于是超参数就只剩下λ和μk了。
这里作者讲到:
Although it is possible to learn a fixed λ and μk, we argue that a performance gain can be obtained if λ and μk vary with two key elements, i.e., scale factor s and noise level σ, that influence the degree of ill-posedness.
于是又用了一个简单的3层全连接层作为超参数 Module 确定α=[α1,α2,…,αk]和β=[β1,β2,…,βk]:
[α,β]=H(σ,s)
# 训练
作者说用的是最基本的L1 Loss,不细看了
# 效果
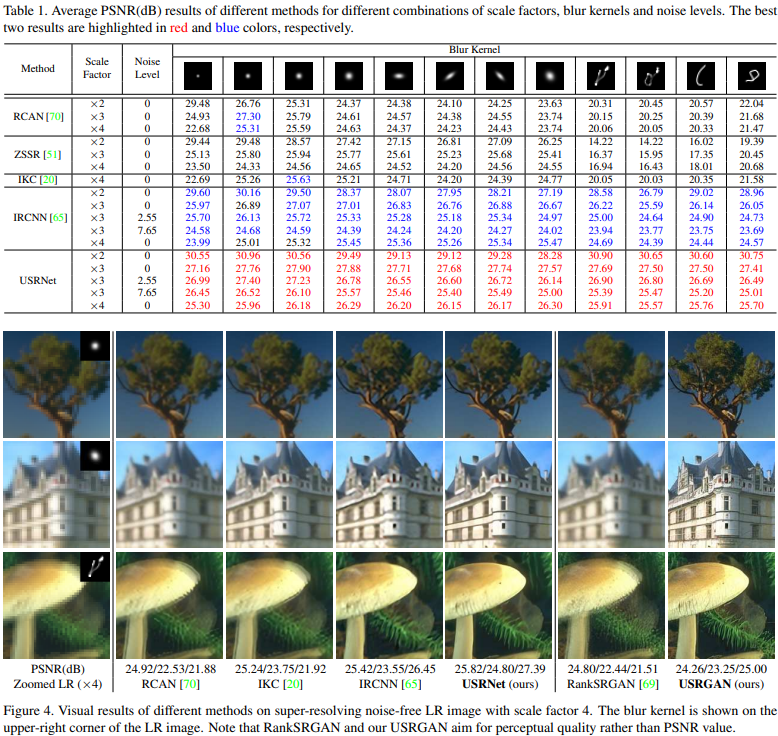

还是很棒的,对不同的模糊核都有很好的效果
