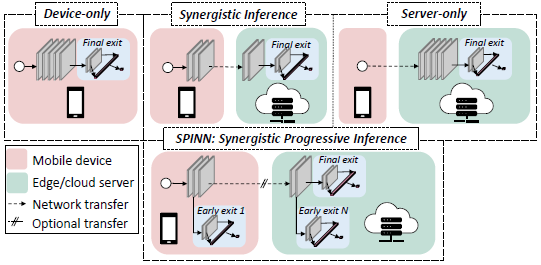
SPINN: Synergistic Progressive Inference of Neural Networks over Device and Cloud
@article{SPINNSynergisticProgressiveInference2020,
title = {{{SPINN}}: {{Synergistic Progressive Inference}} of {{Neural Networks}} over {{Device}} and {{Cloud}}},
shorttitle = {{{SPINN}}},
author = {Laskaridis, Stefanos and Venieris, Stylianos I. and Almeida, Mario and Leontiadis, Ilias and Lane, Nicholas D.},
year = {2020},
month = sep,
pages = {1--15},
doi = {10.1145/3372224.3419194},
archivePrefix = {arXiv},
eprint = {2008.06402},
eprinttype = {arxiv},
journal = {Proceedings of the 26th Annual International Conference on Mobile Computing and Networking},
keywords = {Computer Science - Computer Vision and Pattern Recognition,Computer Science - Distributed; Parallel; and Cluster Computing,Computer Science - Machine Learning,Statistics - Machine Learning},
language = {en}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 摘要
- 本文面向的核心问题:在移动设备上维持高性能计算
- 此问题目前常见的解决方法:将计算任务通过网络发给云计算
- 此解决方法存在的问题:
- 移动设备的网络连接具有动态性和不稳定性
- 不适合对实时性要求较高的应用场景,比如无人机避障
- 本文如何解决这个问题:SPINN
- 本地设备-云协同计算
- progressive inference method
- SPINN核心:
- 一种在运行时动态确定退出策略并对网络进行拆分的调度器
# Introduction
- CNN(卷积神经网络)驱动的应用越来越广泛
- CNN计算量很大,大到在很多移动设备上无法运行
- 现在许多应用提供商采用cloud-centric solutions:将计算任务发送到云端计算再返回结果(Server Only),从而解决算力不够的问题
# Server Only solutions的代价
- 性能极大依赖于网络条件,缺乏网络容错能力
- 在云端托管机器学习计算资源成本很高
- 数据走网络有隐私泄露风险
# Synergistic solutions
部分计算在本地设备完成,部分计算在云端完成
- 和Server Only一样,性能极大依赖于网络条件,缺乏网络容错能力
- 无法适应对多个维度均有严格要求的应用(延迟、吞吐量、正确率、设备和云计算成本)
# SPINN
- 先进的神经网络推理机制,使云端和本地设备上的CNN推理过程高效而可靠
- 在已有的提前退出机制的基础之上,实现了一个early-exit-aware cancellation mechanism:当设备计算出足够准确的结果时中断计算过程,从而最小化冗余的计算和通信量
- 同时,对于不稳定的网络,在实现提前退出方案时考虑了系统的执行能力,以适应云端不可用的情况
- 通过在骨干网中谨慎地放置神经网络出口,保证了系统的响应能力和可靠性,并克服了现有卸载系统的局限性
- 一种CNN专用的中间数据打包方法,利用CNN的弹性(?resilience?什么意思)和稀疏性最大程度上减少传输开销
- 结合了无损和考虑了模型正确率的有损压缩方法
- 考虑到了SLA(服务等级协议)和使用场景的调度器
- 对以下几个方面进行联合优化
- 提前退出策略
- 那些部分在云端算哪些在本地算
- 将用户指定的各种性能参数的重要性权重矩阵翻译为SLA
- 根据实际情况动态地选择可以实现最高性能的策略:
- 通过监视不稳定的网络状况和运行时的资源负载
- 上下文运行时信息
- 先前执行计算的历史数据
- 对以下几个方面进行联合优化
# 已有工作
# 系统概述
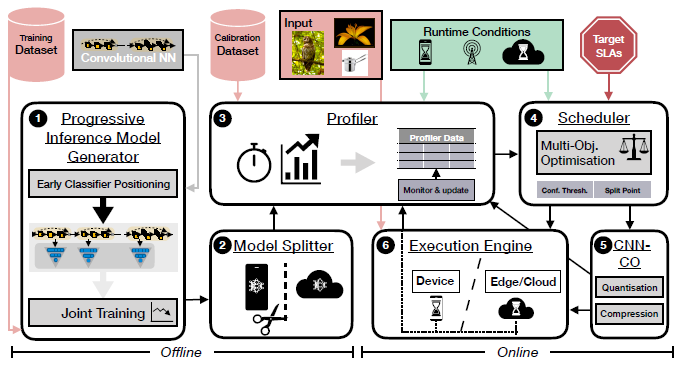
- 离线过程:渐进式推理模型生成器对模型及各个出口进行训练
- 离线过程:模型分割器定位所有可以分割到云端和边缘进行计算的分割点
- 离线过程:离线分析器计算模型的退出概率和每个出口的分类正确率;用历史数据中的客户端和服务器性能作为性能估计初始值
- 在线过程:调度器获取性能估计初始值、目标SLAs、运行时环境情况,决定模型划分方案和提前退出策略
- 在线过程:通信优化器利用CNN的稀疏性和弹性压缩数据
- 在线过程:执行器执行通信和计算过程
- 同时,一个在线分析器时刻监测着执行过程,将收集到的数据作为下一次离线过程的基础数据
# 渐进式推理模型生成器
渐进式推理模型生成器负责从一个CNN模型生成一个渐进式的推理模型。这一过程涉及到三个重要的设计决策:
- 提前退出(提前退出点的数量、位置和结构)
- 训练模式
- 提前退出策略
# 提前退出
- 数量:在SPINN中,提前退出点放置在能将模型按照FLOPS均匀划分计算量的位置。
- 位置:在后面的实验中,提前退出点将放置在15%、13%、...、90%FLOP的位置。
- 结构:将提前退出点的结构视为固定的,并且适配MSDNet(多尺度密集网络),使得每个退出点都有相同的表现力 (提前退出点的“结构”(architecture)是指什么?为什么适配MSDNet?“有相同的表现力”(expressivity)是指什么?)
# 训练模式
提前退出网络的overthinking现象:在浅层网络中分类准确率很高的样本到了深层网络中分类准确率反而变低了。参见论文Shallow-Deep Networks: Understanding and Mitigating Network Overthinking。SPINN使用了这篇论文中介绍的代价函数和训练方法,以克服overthinking现象。
本文所使用的训练模式要求在训练之前固定提前退出点的位置。这种方法虽然不灵活,但是固定提前退出点的位置可以使得退出点处的网络和原始网络一起训练,比把原始网络和退出点处的网络分开单独训练效果更好。(注:BranchyNet里面也是这样做的)
# 提前退出策略
给定一个thrconf值,当某个退出点的softmax层输出的置信度的最大值大于thrconf时就在这里退出。如果前面几层都没有输出大于thrconf的置信度,那就自然从最后一层退出了。
# thrconf对系统的影响
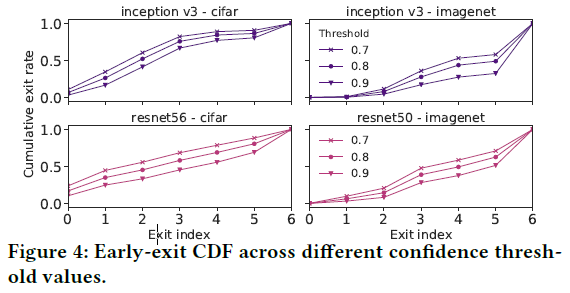
thrconf越大,样本在浅层网络退出的概率越小,越多的的样本在深层的退出点才能退出。进而:
- 计算量越大:显而易见,算的层数越深计算量越大
- 正确率越高:在深层的退出点输出的计算结果显然会有较高的正确率,如下图所示。
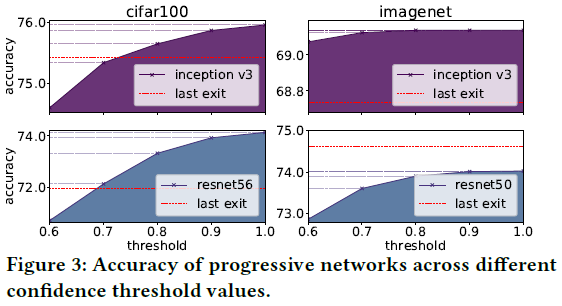
- 红色线表示没有中间退出点的原始网络网络分类正确率。由于overthinking现象的存在,可以看到有些原始网络的分类正确率还不如提前退出网络
因此,thrconf就是调节计算量和正确率的trade off的关键参数。
# 模型分割器
模型分割器负责将渐进式推理模型生成器生成的模型切分为在客户端和在服务器上运行的两个部分。
- 定义可能的切分位置
- 自动地在给定的CNN上查找切分位置
# 切分位置的决策空间
对于一个NL层的网络,如果不限制切成几块,其可能的切分就是2NL−1。但是:
- 服务器算力很强,卸载到服务端上计算的网络进行切分只会增加通信开销
- ReLU层将负值全变成0,其输出有稀疏性
因此,为了方便压缩节约通信成本,SPINN只在ReLU层中选择切分点,并且切分点只用于卸载到服务器之前的网络中。。
# 自动寻找切分位置
- 将神经网络组织为一个执行图
- 寻找所有切分点
- 用上述方法生成切分位置的决策空间
- 由调度器从决策空间中动态地选择切分位置
# 切分位置对系统的影响
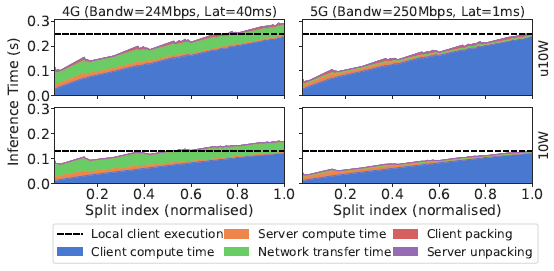
- 客户端计算时间-服务端计算时间-通信时间 trade off
- 在越深的层切分:
- 客户端计算时间越多
- 服务端计算时间越少
- 卸载到服务端的概率越低
- 带宽越小,通信代价越大
- 客户端性能越差,在客户端计算耗时越多
- 在越深的层切分:
# 分析器
# 离线过程
离线过程仅在部署前进行一次
- 对神经网络进行分析:
- 对所有切分方案下都计算数据传输量
- 在不同thrconf下计算平均正确率
- 对设备进行分析:
- 估计到每个切分点s的计算时间Toffline⟨s⟩
# 在线过程
将离线过程的结果作为初始数据。
- 估计客户端上的延迟:
- 测量计算到某个切分点s的计算时间Treal⟨s⟩
- 计算延迟缩放参数SF=Toffline⟨s⟩Treal⟨s⟩
- 更新其他点s′的离线估计值为SF⋅Toffline⟨s′⟩
- 估计服务器上的延迟:
- 如果服务器端能直接返回计算时间Tserver⟨s⟩,那就可以直接计算SF
- 如果服务器端不支持返回计算时间
- 那就通过总时间和网络带宽估计计算时间Tserver⟨s⟩=Tresponse⟨s,e⟩−(L+BDresponse)
- Tresponse⟨s,e⟩:返回结果的总耗时
- Dresponse:返回的总数据量
- B和L:网络的瞬时带宽和瞬时延迟估计值,在传输过程中通过滑动平均计算得到
- 那就通过总时间和网络带宽估计计算时间Tserver⟨s⟩=Tresponse⟨s,e⟩−(L+BDresponse)
# 动态调度器
- 优化变量σ=⟨s,thrconf⟩:切分点位置和每个出口的置信度
- 优化目标M=⟨latency,throughput,servercost,devicecost,accuracy⟩:延迟、吞吐量、服务器负载、设备负载、正确率,每个优化目标方程都转化成取值越小越好的形式
- 优化方法:
- 用户指定M中的所有优化目标的硬性限制,系统从σ可行值中剔除不可行的解
- 用户对M中的所有优化目标进行排序,系统在σ的可行解上进行字典序多目标规划
字典序多目标规划:
s.t.σminMi(σ)Mj(σ)≤Mj(σj∗)i,j∈N+,j<i≤∣M∣
即,对于第i个优化目标Mi,在优化过程中除了需要调整σ使得Mi(σ)尽可能小之外,还需要保证前面所有优化项的值Mj(σ)不能比之前的优化结果Mj(σj∗)更差。
# 通信优化器
通信优化器中所使用的算法都是前人已经实现的算法。
- 压缩模型:
- 权值缩减
- 量化神经网络(QNN)
- 压缩数据:先估计一下压缩时间和压缩后所能节约的传输时间,如果总时间确实能减少那就执行压缩
# 分布式执行引擎
- 每到达一个退出位置,都将置信度和设定的阈值相比较,如果大于阈值则退出
- 数据的传输和计算分为两个线程并行地执行
- 云端推断和本地推断同时进行,如果本地推断先出了结果,就向云端发信息让其退出推断过程,以节约资源(云端可能有网络波动或暂时断线,导致本地出结果先于云端返回结果)
# 实验
# 网速变化时,推断速度如何变化?
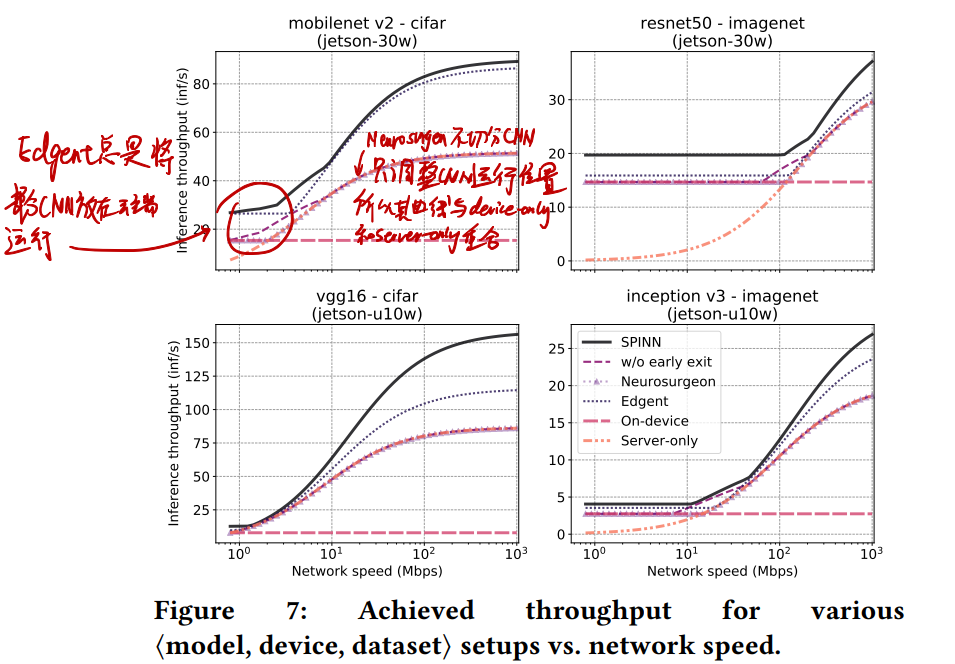
- 由于Neurosurgeon不切分网络,只调整运行位置,因此其曲线要么与Server-Only重合,要么与Device-Only重合
- 低带宽下:全部在设备上执行,SPINN有提前退出,别人没有,于是性能高
- 中等带宽下:SPINN有动态切分,别人没有,于是性能高
- 高带宽下:全部在服务端运行,SPINN有提前退出,别人没有,于是性能高
- 从w/o early exit可以看出,失去了提前退出,SPINN性能只相当于Neurosurgeon,只是有动态切分让它在过渡的区域性能较好
# 服务器负载变化时,推断速度如何变化?
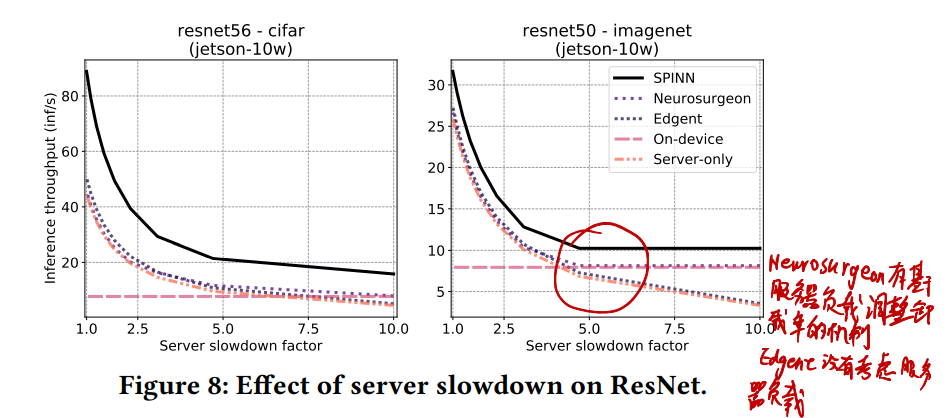
- Neurosurgeon和SPINN都有基于服务器负载调整策略的机制,Edgent没有,于是服务器高负载下Edgent性能低
# 不同延迟限制下,服务端推断时间和准确率如何变化?
延迟限制和推断准确率是一对trade-off,延迟要求高了,调度器会降低置信度阈值使更多的推断在本地退出,进而正确率下降。
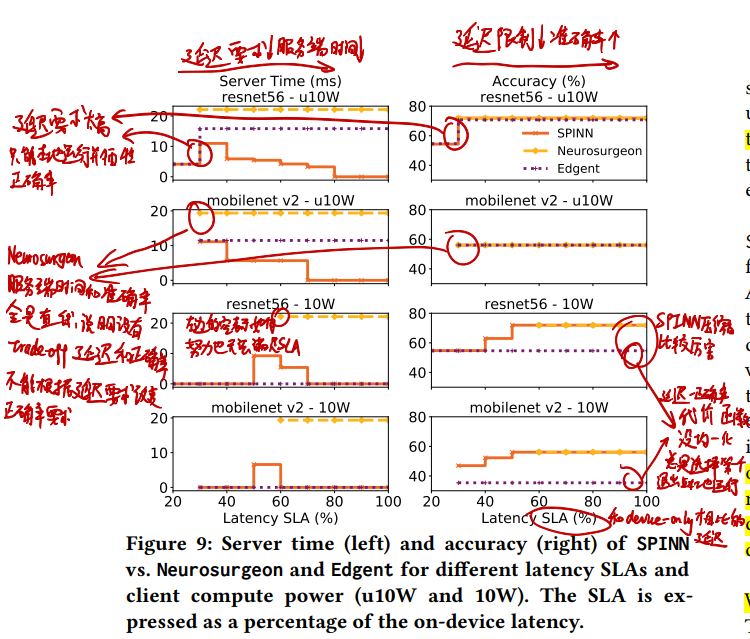
- Neurosurgeon的线全是直线,延迟限制强了直接没有数据,说明它没有做延迟限制相关的trade-off
- 延迟限制由弱变强时,SPINN会更多地将推断放到服务端以降低延迟;而延迟限制太强时,SPINN只能降低正确率要求(退出阈值)并且进行本地推断以适应延迟需求
- 相比Edgent,SPINN胜在了有提前退出和用了牛逼的压缩算法
# 网络动态变化时,SPINN切分点位置、置信度阈值和推断速度如何变化?

- 带宽低,置信度阈值低,提前退出多,但实验显示推断准确率下降小于1%
- 带宽高,切分点靠近起点,推断速度提升大
# 能耗

- 越靠出口的神经网络中间层输出数据量越小,因此切分点选的太靠近入口反而能耗大
# 服务器掉线和丢包时的情况
用单出口模型+SPINN动态切分作为baseline

- 由于多出口模型有提前退出,不全依赖服务器,所以对服务器掉线和丢包都有很好的适应性
- 不仅整体效果好,受切分点位置影响也小
- 数据集越复杂,越不容易提前退出,多出口模型效果越差,受服务器掉线和丢包影响也就越大,imagenet+resnet50就是如此