Server-Driven Video Streaming for Deep Learning Inference
Howard Yin 2021-03-27 14:44:02 论文笔记目标跟踪云计算
@inproceedings{ServerDrivenVideoStreamingDeep2020,
title = {Server-{{Driven Video Streaming}} for {{Deep Learning Inference}}},
booktitle = {Proceedings of the {{Annual}} Conference of the {{ACM Special Interest Group}} on {{Data Communication}} on the Applications, Technologies, Architectures, and Protocols for Computer Communication},
author = {Du, Kuntai and Pervaiz, Ahsan and Yuan, Xin and Chowdhery, Aakanksha and Zhang, Qizheng and Hoffmann, Henry and Jiang, Junchen},
date = {2020-07-30},
pages = {557--570},
publisher = {{ACM}},
location = {{Virtual Event USA}},
doi = {10.1145/3387514.3405887},
url = {https://dl.acm.org/doi/10.1145/3387514.3405887},
urldate = {2021-01-24},
eventtitle = {{{SIGCOMM}} '20: {{Annual}} Conference of the {{ACM Special Interest Group}} on {{Data Communication}} on the Applications, Technologies, Architectures, and Protocols for Computer Communication},
isbn = {978-1-4503-7955-7},
langid = {english}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 概述
# 应用场景
- 摄像头向服务器传输视频
- 服务器DNN执行目标检测或语义分割
- 网速不足以支持高清视频
# 传统方法
- 根据网速情况调整传输视频的清晰度
- 摄像头先判断图像的重点区域,只传输这些重点区域
# 本文方法
- 摄像头先传低清帧
- 服务器端的DNN反馈重点区域给摄像头
- 摄像头再把重点区域发给服务器端进一步识别
# Introduction
# 视频流领域的关键设计问题:在何处进行优化决策
# Source-Driven:在视频流源端进行优化决策
- 常见于视频播放应用:Youtube、Netflix等
- 常见的框架:DASH(Dynamic Adaptive Streaming over HTTP)
Source-Driven适用的前提:
- application-level quality可以被Source端知晓
- Destination端的user experience无法实时测量
# 实时目标识别领域Source-Driven为什么不好?
在实时目标识别领域,Source-Driven意味着摄像头需要承担优化任务:决定视频流质量、决定传帧的哪些部分等
Source-Driven前提不满足:
- Source端(摄像头)无法估计application-level quality(服务器上的识别准确率)
- Destination端(服务器)的user experience(DNN输出的置信度)可以实时测量
# 本文如何解决这个问题:DDS(DNN-Driven Streaming)
根据服务端的DNN输出进行优化决策
- 摄像头先传低清帧
- 服务器端的DNN反馈低清晰度上的识别结果给摄像头
- 摄像头根据反馈的识别结果把重点区域发给服务器端进一步识别
# 挑战:DNN反馈哪些识别结果
本文主要关注于三个领域:
- 目标检测
- 语义分割
- 面部识别
观察到的现象:低质图虽然不能给推断带来高正确率,但可以很好地找出疑似目标的位置
# 现有的类似解决方案
- 由摄像头判断哪些位置重要
- RPN(region-proposal networks):一种专用于判断图像重点区域位置的网络
- 缺陷:RPN只在目标较大时效果好;不适用于语义分割
- 注意力机制
- 与本文非常类似,都是关注于重点区域
# Motivation
# 强终端vs弱终端+强服务器:省钱!
弱终端+强服务器:NVIDIA Tesla T4 GPU (with a throughput of running ResNet50 at 5,700FPS) costs $23 × 60(cameras)+$2000(GPU)= $3.4K
强终端:60 NVIDIA Jetson TX2 cameras (each running ResNet50 at 89FPS) costs about $400×60 = $24K
# 性能参数
- Accuracy:本文的识别结果和DNN直接处理高清全图的结果之间的相似性
- Bandwidth usage:数据传输量/时间
- Average response delay (freshness):处理时间/识别目标数量(或语义分割中的像素数量)
# 可以进行设计的部分
- Leveraging camera-side compute power:使用相机提前去除无用部分
- 缺点:由于性能限制,精度很低
- Model distillation:裁剪模型
- 缺点:This approach is efficient only in training smaller DNNs that work well on less expensive hardware.(没懂,什么意思)
- Video codec optimization:使用基于内容的编码方式
- Temporal configuration adaptation:基于视频内容调整帧码率
- 一帧只能一种编码,无法适应帧内部的内容分布不均
- Spatial quality adaptation:根据帧内部的内容分布调整不同区域的码率
# 潜在的优化空间
- 给人看的视频流要求每个地方都清晰,要有背景,还要流畅回放,给机器看的视频不需要这些
- 一个视频里,有50%~80%的视频帧中目标像素少于20%
因此,根据帧内内容分布裁剪背景是一个很好的选择。
# 现有方法的局限性
- 相机侧进行切分:算力不足以支持精确的算法
- 服务侧全部包办:消耗大量带宽,一点点的性能提升就要多耗费巨大的带宽资源
# 系统设计
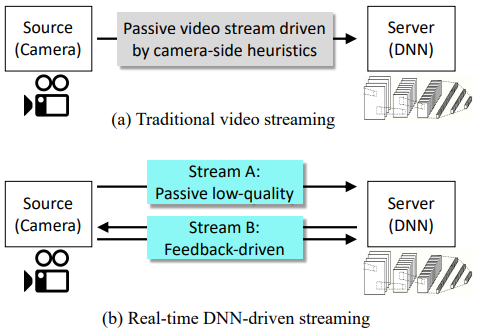
# Server-Driven和传统Source-Driven对比👇
# 哪些区域需要高清?👇
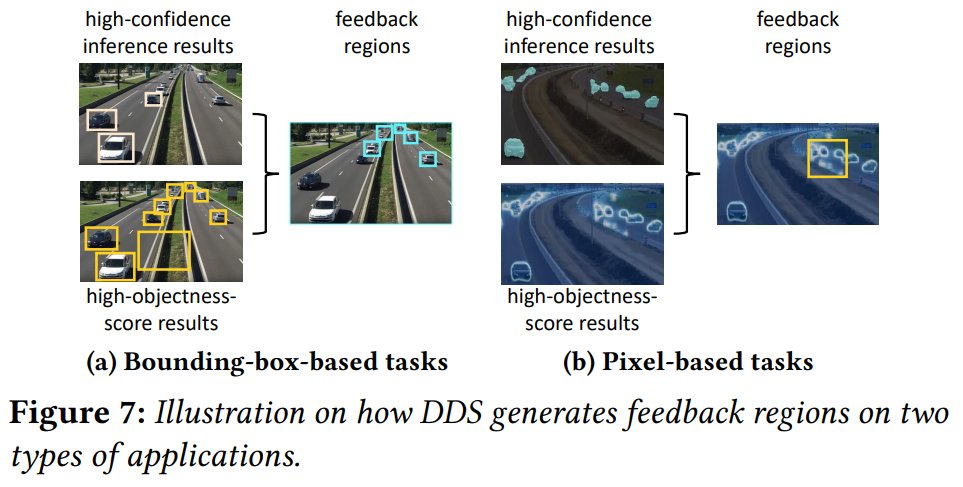
- 目标检测应用(结果为很多框,每个框对每个标签都有一个分数)
- 哪些区域不用高清feedback region:分数很高的框、很大的框
- 哪些区域需要高清feedback region:除上述框之外的所有识别出目标的框都要高清
- 语义分割应用(结果为每个像素对每个标签都有一个分数)
- 哪些区域需要高清feedback region:分数最高的标签和分数第二高的标签分数差小的像素
- 用框框住尽可能多的高分数差像素
- 哪些区域需要高清feedback region:分数最高的标签和分数第二高的标签分数差小的像素
# 如何适应变化的带宽?
- 依据:上一帧传输时的所用带宽、当前待传输帧的可用带宽(通过卡尔曼滤波估计)
- 调节:高清视频流清晰度、低清视频流清晰度
# 如何传帧局部?
- 将feedback region之外的区域置0,让视频编码器去压缩