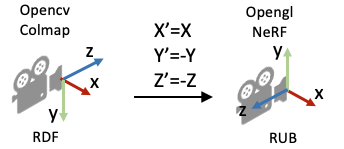原文
原文
原文
《视觉 SLAM 十四讲》高翔
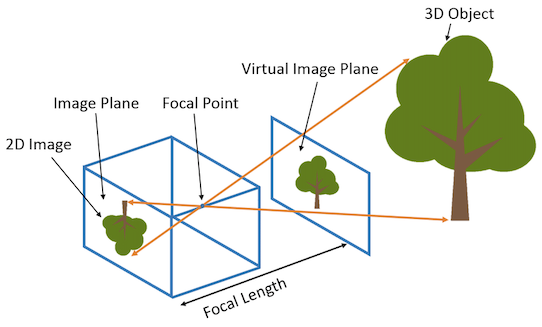
总体概览 NeRF的技术其实很简洁,并不复杂。但与2D视觉里考虑的2维图像不同,NeRF考虑的是一个3D空间。下面列的是NeRF实现的几个关键部分:
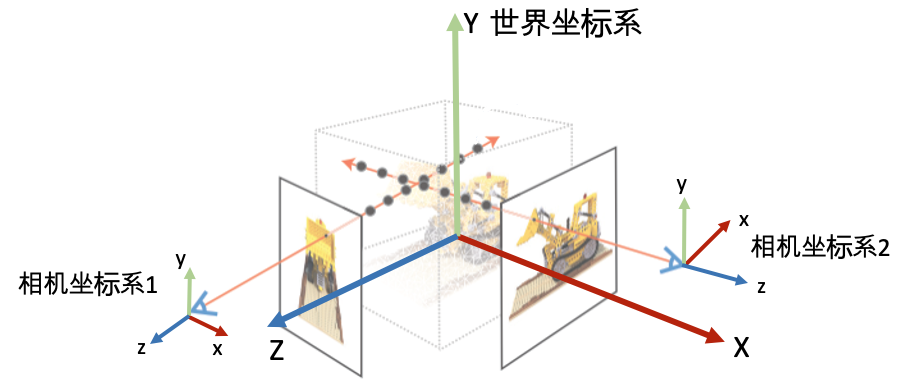
有一个 3D空间 ,用一个连续的场表示 空间里存在一个感兴趣的 物体区域 处于 不同位置和朝向的相机 拍摄多视角图像 对于一张 图像 ,根据相机中心和图像平面的一个像素点,两点确定一条 射线 穿过3D空间 在射线上采样多个离散的 3D点 并利用体素渲染像素的颜色。 这里面涉及到3D空间、物体区域、相机位置和朝向、图像、射线、以及3D采样点等。要想优化NeRF,我们需要能够表达刚刚提到的这些东西。
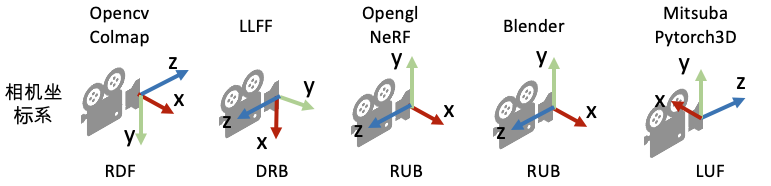
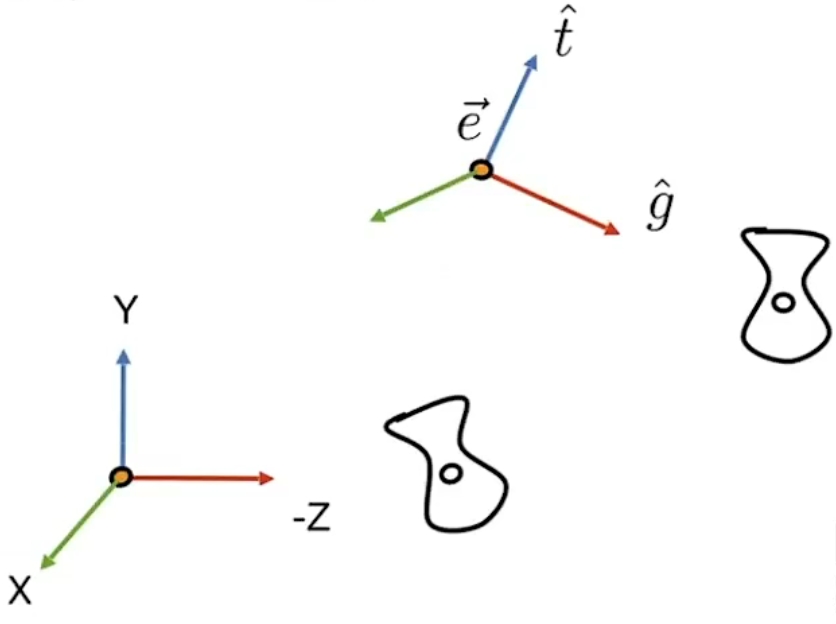
坐标系定义: 为了唯一地描述每一个空间点的坐标,以及相机的位置和朝向,我们需要先定义一个世界坐标系。一个坐标系其实就是由原点的位置与XYZ轴的方向决定。接着,为了建立3D空间点到相机平面的映射关系以及多个相机之间的相对关系,我们会对每一个相机定义一个局部的相机坐标系。下图为常见的坐标系定义习惯。
相机的内外参数 相机的位置和朝向由相机的外参(extrinsic matrix)决定,投影属性由相机的内参(intrinsic matrix)决定。
注意:接下来的介绍假设矩阵是 列矩阵(column-major matrix) ,变换矩阵 左乘 坐标向量实现坐标变换(这也是OpenCV/OpenGL/NeRF里使用的形式)。
文中会混用齐次坐标 和一般坐标,为避免混乱建议先学一下齐次坐标 。
6DoF和相机外参 首先,先解释一下自由度,自由度与刚体在空间中的运动相关。可以理解为物体移动的不同基本方式。
平移运动:刚体可以在3个自由度中平移:向前/后,向上/下,向左/右
旋转运动:刚体在3个自由度中旋转:纵摇(Pitch)、横摇(Roll)、垂摇(Yaw)
因此,3种类型的平移自由度+3种类型的旋转自由度 = 6自由度
在任意一个自由度中,物体可以沿两个“方向”自由运动。例如,电梯限制在1个自由度中(垂直平移),但电梯能够在这个自由度中上下运动。同样,摩天轮限制在1个自由度中,但这是旋转自由度,所以摩天轮能够朝相反的方向旋转。
我们可以继续举例子,比如说主题公园。碰碰车总共有3个自由度:它只能在3轴中的2条里平移(无法像电梯那样上下移动);然后它只能以一种方式旋转(无法像飞机那样纵摇和垂摇)。 所以2个平移+1个旋转=3自由度。
无论有多复杂,刚体的任何可能性运动都可以通过6自由度的组合进行表达。 例如在你用球拍击打网球的时候,球拍的复杂运动可以表示为平移和旋转的组合。
对相机再这6个自由度的数值描述即相机外参。
相机外参是一个4x4的矩阵,其作用是计算世界坐标系的某个点[ x w , y w , z w ] T [x_w,y_w,z_w]^T [ x w , y w , z w ] T [ x p , y p , z p ] T [x_p,y_p,z_p]^T [ x p , y p , z p ] T world-to-camera (w2c)矩阵 。
相机外参:w2c矩阵 w2c矩阵[ R ∣ t ] [\bm R|\bm t] [ R ∣ t ] [ x w , y w , z w ] T [x_w,y_w,z_w]^T [ x w , y w , z w ] T [ x c , y c , z c ] T [x_c,y_c,z_c]^T [ x c , y c , z c ] T
[ x c y c z c ] = [ R ∣ t ] ⋅ [ x w y w z w 1 ] = [ r 11 r 12 r 13 t 1 r 21 r 22 r 23 t 2 r 31 r 32 r 33 t 3 ] ⋅ [ x w y w z w 1 ] = [ r 11 r 12 r 13 r 21 r 22 r 23 r 31 r 32 r 33 ] ⋅ [ x w y w z w ] + [ t 1 t 2 t 3 ] = R ⋅ [ x w y w z w ] + t \left[
\begin{matrix}
x_c\\y_c\\z_c
\end{matrix}
\right]
=
[\bm R|\bm t]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w\\1
\end{matrix}
\right]
=
\left[
\begin{matrix}
r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&t_3
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w\\1
\end{matrix}
\right]
=
\left[
\begin{matrix}
r_{11}&r_{12}&r_{13}\\r_{21}&r_{22}&r_{23}\\r_{31}&r_{32}&r_{33}
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w
\end{matrix}
\right]
+
\left[
\begin{matrix}
t_1\\t_2\\t_3
\end{matrix}
\right]
=
\bm R
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w
\end{matrix}
\right]
+
\bm t
⎣ ⎢ ⎡ x c y c z c ⎦ ⎥ ⎤ = [ R ∣ t ] ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x w y w z w 1 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎡ r 1 1 r 2 1 r 3 1 r 1 2 r 2 2 r 3 2 r 1 3 r 2 3 r 3 3 t 1 t 2 t 3 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x w y w z w 1 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎡ r 1 1 r 2 1 r 3 1 r 1 2 r 2 2 r 3 2 r 1 3 r 2 3 r 3 3 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎡ x w y w z w ⎦ ⎥ ⎤ + ⎣ ⎢ ⎡ t 1 t 2 t 3 ⎦ ⎥ ⎤ = R ⋅ ⎣ ⎢ ⎡ x w y w z w ⎦ ⎥ ⎤ + t
稍微思考一下,其实 R \bm R R t \bm t t 旋转 和平移 。
乘上R \bm R R [ x w , y w , z w ] T [x_w,y_w,z_w]^T [ x w , y w , z w ] T t \bm t t − t -\bm t − t t \bm t t 世界坐标系原点在相机坐标系下的位置 。其计算结果[ x c , y c , z c ] T [x_c,y_c,z_c]^T [ x c , y c , z c ] T
[ x c y c z c ] = [ r 11 r 12 r 13 t 1 r 21 r 22 r 23 t 2 r 31 r 32 r 33 t 3 ] ⋅ [ x w y w z w 1 ] \left[
\begin{matrix}
x_c\\y_c\\z_c
\end{matrix}
\right]
=
\left[
\begin{matrix}
r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&t_3
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w\\1
\end{matrix}
\right]
⎣ ⎢ ⎡ x c y c z c ⎦ ⎥ ⎤ = ⎣ ⎢ ⎡ r 1 1 r 2 1 r 3 1 r 1 2 r 2 2 r 3 2 r 1 3 r 2 3 r 3 3 t 1 t 2 t 3 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x w y w z w 1 ⎦ ⎥ ⎥ ⎥ ⎤
正因为这项功能,所以相机的外参[ R ∣ t ] [\bm R|\bm t] [ R ∣ t ]
相机外参逆矩阵:c2w矩阵 因为NeRF主要使用c2w,这里再简要介绍一下c2w的含义。
相机外参的逆矩阵被称为 camera-to-world (c2w)矩阵 ,其作用是把相机坐标系的点变换到世界坐标系:
[ R ∣ t ] − 1 ⋅ [ x c y c z c 1 ] = [ x w y w z w ] [\bm R|\bm t]^{-1}
\cdot
\left[
\begin{matrix}
x_c\\y_c\\z_c\\1
\end{matrix}
\right]
=
\left[
\begin{matrix}
x_w\\y_w\\z_w
\end{matrix}
\right]
[ R ∣ t ] − 1 ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x c y c z c 1 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎡ x w y w z w ⎦ ⎥ ⎤
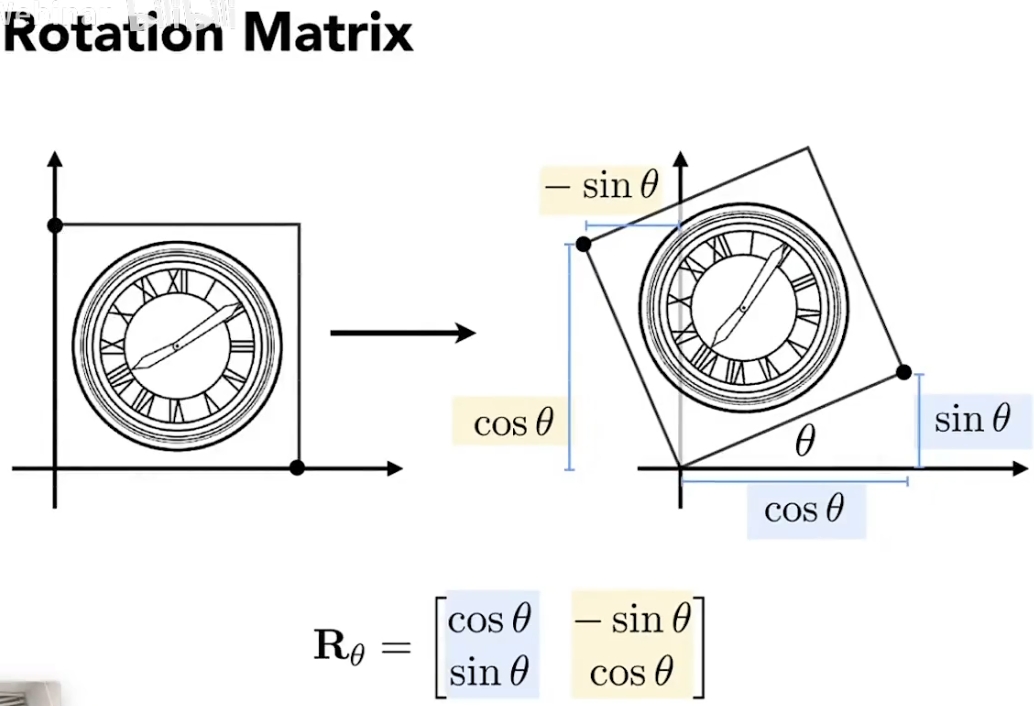
对旋转矩阵的理解 二维的旋转矩阵可以看作是把单位向量拉到指定的两个夹角90°的单位向量上:
拓展到三维:
绕x轴旋转α \alpha α [ 1 , 0 , 0 ] T [1,0,0]^T [ 1 , 0 , 0 ] T [ 0 , 1 , 0 ] T [0,1,0]^T [ 0 , 1 , 0 ] T [ 0 , 0 , 1 ] T [0,0,1]^T [ 0 , 0 , 1 ] T [ 0 , cos α , sin α ] T [0,\cos\alpha,\sin\alpha]^T [ 0 , cos α , sin α ] T [ 0 , − sin α , cos α ] T [0,-\sin\alpha,\cos\alpha]^T [ 0 , − sin α , cos α ] T
R x ( α ) = [ 1 0 0 0 cos α − sin α 0 sin α cos α ] \bm R_x(\alpha)=\left[
\begin{matrix}
1&0&0\\
0&\cos\alpha&-\sin\alpha\\
0&\sin\alpha&\cos\alpha\\
\end{matrix}
\right]
R x ( α ) = ⎣ ⎢ ⎡ 1 0 0 0 cos α sin α 0 − sin α cos α ⎦ ⎥ ⎤
绕y轴旋转α \alpha α [ 0 , 1 , 0 ] T [0,1,0]^T [ 0 , 1 , 0 ] T [ 1 , 0 , 0 ] T [1,0,0]^T [ 1 , 0 , 0 ] T [ 0 , 0 , 1 ] T [0,0,1]^T [ 0 , 0 , 1 ] T [ cos α , 0 , − sin α ] T [\cos\alpha,0,-\sin\alpha]^T [ cos α , 0 , − sin α ] T [ sin α , 0 , cos α ] T [\sin\alpha,0,\cos\alpha]^T [ sin α , 0 , cos α ] T
R y ( α ) = [ cos α 0 sin α 0 1 0 − sin α 0 cos α ] \bm R_y(\alpha)=\left[
\begin{matrix}
\cos\alpha&0&\sin\alpha\\
0&1&0\\
-\sin\alpha&0&\cos\alpha\\
\end{matrix}
\right]
R y ( α ) = ⎣ ⎢ ⎡ cos α 0 − sin α 0 1 0 sin α 0 cos α ⎦ ⎥ ⎤
绕z轴旋转α \alpha α [ 0 , 0 , 1 ] T [0,0,1]^T [ 0 , 0 , 1 ] T [ 1 , 0 , 0 ] T [1,0,0]^T [ 1 , 0 , 0 ] T [ 0 , 1 , 0 ] T [0,1,0]^T [ 0 , 1 , 0 ] T [ cos α , sin α , 0 ] T [\cos\alpha,\sin\alpha,0]^T [ cos α , sin α , 0 ] T [ − sin α , cos α , 0 ] T [-\sin\alpha,\cos\alpha,0]^T [ − sin α , cos α , 0 ] T
R z ( α ) = [ cos α − sin α 0 sin α cos α 0 0 0 1 ] \bm R_z(\alpha)=\left[
\begin{matrix}
\cos\alpha&-\sin\alpha&0\\
\sin\alpha&\cos\alpha&0\\
0&0&1\\
\end{matrix}
\right]
R z ( α ) = ⎣ ⎢ ⎡ cos α sin α 0 − sin α cos α 0 0 0 1 ⎦ ⎥ ⎤
给定上述这些简单的旋转,可以组合出任意的三维空间中的旋转,对应的α , β , γ \alpha,\beta,\gamma α , β , γ
进一步,空间中绕轴n n n α \alpha α R ( n , α ) \bm R(\bm n,\alpha) R ( n , α )
R ( n , α ) = cos ( α ) I + ( 1 − cos α ) n n T + sin α [ 0 − n z n y n z 0 − n x − n y n x 0 ] \bm R(\bm n,\alpha)=\cos(\alpha)\bm I+(1-\cos\alpha)\bm n\bm n^T+\sin\alpha
\left[
\begin{matrix}
0&-n_z&n_y\\
n_z&0&-n_x\\
-n_y&n_x&0
\end{matrix}
\right]
R ( n , α ) = cos ( α ) I + ( 1 − cos α ) n n T + sin α ⎣ ⎢ ⎡ 0 n z − n y − n z 0 n x n y − n x 0 ⎦ ⎥ ⎤
刚刚接触的时候,对这个c2w矩阵的值可能会比较陌生。其实c2w矩阵的值直接描述了相机坐标系的朝向和原点。下面来深入理解一下。
如图所示,相机从上一位姿移动到当前位姿,以当前位姿为坐标系,相机原点从[ x e , y e , z e ] T [x_e,y_e,z_e]^T [ x e , y e , z e ] T g ^ \hat g g ^ t ^ \hat t t ^ g ^ \hat g g ^ t ^ \hat t t ^ g ^ × t ^ \hat g\times\hat t g ^ × t ^ M v i e w M_{view} M v i e w
我们可以将相机的移位看成一个位移和一个旋转操作M v i e w = R v i e w T v i e w M_{view}=R_{view}T_{view} M v i e w = R v i e w T v i e w [ x e , y e , z e ] T [x_e,y_e,z_e]^T [ x e , y e , z e ] T − [ x e , y e , z e ] T -[x_e,y_e,z_e]^T − [ x e , y e , z e ] T
T v i e w = [ 1 0 0 − x e 0 1 0 − y e 0 0 1 − z e 0 0 0 1 ] T_{view}=\left[
\begin{matrix}
1&0&0&-x_e\\
0&1&0&-y_e\\
0&0&1&-z_e\\
0&0&0&1\\
\end{matrix}
\right]
T v i e w = ⎣ ⎢ ⎢ ⎢ ⎡ 1 0 0 0 0 1 0 0 0 0 1 0 − x e − y e − z e 1 ⎦ ⎥ ⎥ ⎥ ⎤
将-Z轴和Y轴g ^ \hat g g ^ t ^ \hat t t ^ g ^ \hat g g ^ t ^ \hat t t ^ [ 0 , 0 , − 1 ] [0,0,-1] [ 0 , 0 , − 1 ] [ 0 , 1 , 0 ] [0,1,0] [ 0 , 1 , 0 ] g ^ \hat g g ^ t ^ \hat t t ^ t ^ × ( − g ^ ) = g ^ × t ^ \hat t\times(-\hat g)=\hat g\times\hat t t ^ × ( − g ^ ) = g ^ × t ^ t ^ \hat t t ^ − g ^ -\hat g − g ^
R v i e w − 1 = [ x g ^ × t ^ x t ^ x − g ^ 0 y g ^ × t ^ y t ^ y − g ^ 0 z g ^ × t ^ z t ^ z − g ^ 0 0 0 0 1 ] R_{view}^{-1}=\left[
\begin{matrix}
x_{\hat g\times\hat t}&x_{\hat t}&x_{-\hat g}&0\\
y_{\hat g\times\hat t}&y_{\hat t}&y_{-\hat g}&0\\
z_{\hat g\times\hat t}&z_{\hat t}&z_{-\hat g}&0\\
0&0&0&1\\
\end{matrix}
\right]
R v i e w − 1 = ⎣ ⎢ ⎢ ⎢ ⎡ x g ^ × t ^ y g ^ × t ^ z g ^ × t ^ 0 x t ^ y t ^ z t ^ 0 x − g ^ y − g ^ z − g ^ 0 0 0 0 1 ⎦ ⎥ ⎥ ⎥ ⎤
进而可求R v i e w R_{view} R v i e w
R v i e w = R v i e w − T = [ x g ^ × t ^ y g ^ × t ^ z g ^ × t ^ 0 x t ^ y t ^ z t ^ 0 x − g ^ y − g ^ z − g ^ 0 0 0 0 1 ] R_{view}=R_{view}^{-T}=\left[
\begin{matrix}
x_{\hat g\times\hat t}&y_{\hat g\times\hat t}&z_{\hat g\times\hat t}&0\\
x_{\hat t}&y_{\hat t}&z_{\hat t}&0\\
x_{-\hat g}&y_{-\hat g}&z_{-\hat g}&0\\
0&0&0&1\\
\end{matrix}
\right]
R v i e w = R v i e w − T = ⎣ ⎢ ⎢ ⎢ ⎡ x g ^ × t ^ x t ^ x − g ^ 0 y g ^ × t ^ y t ^ y − g ^ 0 z g ^ × t ^ z t ^ z − g ^ 0 0 0 0 1 ⎦ ⎥ ⎥ ⎥ ⎤
所以就可算出M v i e w = R v i e w T v i e w M_{view}=R_{view}T_{view} M v i e w = R v i e w T v i e w
这里的M v i e w M_{view} M v i e w
相机内参 刚刚介绍了相机的外参,现在简单介绍一下相机的内参。
具体参数怎么来的请看投影和光栅化 中的讲解
相机的内参矩阵将相机坐标系下的3D坐标映射到2D的图像平面,这里以针孔相机(Pinhole camera)为例介绍相机的内参矩阵K:
K = [ f x 0 c x 0 f y c y 0 0 1 ] K=\left[
\begin{matrix}
f_x&0&c_x\\0&f_y&c_y\\0&0&1
\end{matrix}
\right]
K = ⎣ ⎢ ⎡ f x 0 0 0 f y 0 c x c y 1 ⎦ ⎥ ⎤
内参矩阵K包含4个值,其中f x f_x f x f y f_y f y 焦距 (对于理想的针孔相机,f x = f y f_x=f_y f x = f y c x c_x c x c y c_y c y c x c_x c x c y c_y c y
if K is None :
K = np. array( [
[ focal, 0 , 0.5 * W] ,
[ 0 , focal, 0.5 * H] ,
[ 0 , 0 , 1 ]
] )
1 2 3 4 5 6 7
相机内参的真正含义还需要配合一张图和另一种公式写法来解释:
z p [ u v 1 ] = [ f x 0 c x 0 f y c y 0 0 1 ] ⋅ [ x c y c z c ] = z c [ f x x c z c + c x f y y c z c + c y 1 ] z_p
\left[
\begin{matrix}
u\\v\\1
\end{matrix}
\right]
=
\left[
\begin{matrix}
f_x&0&c_x\\0&f_y&c_y\\0&0&1
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
x_c\\y_c\\z_c
\end{matrix}
\right]
=
z_c
\left[
\begin{matrix}
f_x\frac{x_c}{z_c}+c_x\\f_y\frac{y_c}{z_c}+c_y\\1
\end{matrix}
\right]
z p ⎣ ⎢ ⎡ u v 1 ⎦ ⎥ ⎤ = ⎣ ⎢ ⎡ f x 0 0 0 f y 0 c x c y 1 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎡ x c y c z c ⎦ ⎥ ⎤ = z c ⎣ ⎢ ⎡ f x z c x c + c x f y z c y c + c y 1 ⎦ ⎥ ⎤
这里,z p z_p z p z c u = x p z_cu=x_p z c u = x p z c v = y p z_cv=y_p z c v = y p z p z_p z p [ x c , y c , z c ] T [x_c,y_c,z_c]^T [ x c , y c , z c ] T 根据目标点给出成像距离与目标点在成像平面上的位置关系 。
其中的z c z_c z c z p z_p z p z p = z c z_p=z_c z p = z c z p = z c z_p=z_c z p = z c
所以相机内参的真正表现形式应该是:
x p z p = f x x c z c + c x y p z p = f y y c z c + c y \begin{aligned}
\frac{x_p}{z_p}&=f_x\frac{x_c}{z_c}+c_x\\
\frac{y_p}{z_p}&=f_y\frac{y_c}{z_c}+c_y
\end{aligned}
z p x p z p y p = f x z c x c + c x = f y z c y c + c y
联系上文f x f_x f x f y f_y f y c x c_x c x c y c_y c y
反过来理解,从成像反推坐标的过程:
z p K − 1 [ u v 1 ] = [ x c y c z c ] z_p
\bm K^{-1}
\left[
\begin{matrix}
u\\v\\1
\end{matrix}
\right]
=
\left[
\begin{matrix}
x_c\\y_c\\z_c
\end{matrix}
\right]
z p K − 1 ⎣ ⎢ ⎡ u v 1 ⎦ ⎥ ⎤ = ⎣ ⎢ ⎡ x c y c z c ⎦ ⎥ ⎤
很显然,这里z p = z c z_p=z_c z p = z c z p z_p z p z c z_c z c x c , y c , z c x_c,y_c,z_c x c , y c , z c
如何获得相机参数 NeRF算法假设相机的内外参数是提供的,那么怎么得到所需要的相机参数呢?这里分合成数据集和真实数据集两种情况。
合成数据 对于合成数据集,我们需要通过指定相机参数来渲染图像,所以得到图像的时候已经知道对应的相机参数,比如像NeRF用到的Blender Lego数据集。常用的渲染软件还有Mitsuba、OpenGL、PyTorch3D、Pyrender等。渲染数据比较简单,但是把得到的相机数据转到NeRF代码坐标系牵扯到坐标系之间的变换,有时候会比较麻烦。
直接线性变换(DLT) DLT的目标是求解出矩阵P = { p i j } 3 × 4 \bm P=\{p_{ij}\}_{3\times 4} P = { p i j } 3 × 4 [ x w , y w , z w ] T [x_w,y_w,z_w]^T [ x w , y w , z w ] T [ x p , y p , z p ] T [x_p,y_p,z_p]^T [ x p , y p , z p ] T
[ x p y p z p ] = W ⋅ [ x w y w z w ] + b = [ p 11 p 12 p 13 p 21 p 22 p 23 p 31 p 32 p 33 ] ⋅ [ x w y w z w ] + [ p 14 p 24 p 34 ] \left[
\begin{matrix}
x_p\\y_p\\z_p
\end{matrix}
\right]
=\bm W
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w
\end{matrix}
\right]
+\bm b
=
\left[
\begin{matrix}
p_{11}&p_{12}&p_{13}\\p_{21}&p_{22}&p_{23}\\p_{31}&p_{32}&p_{33}
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w
\end{matrix}
\right]
+
\left[
\begin{matrix}
p_{14}\\p_{24}\\p_{34}
\end{matrix}
\right]
⎣ ⎢ ⎡ x p y p z p ⎦ ⎥ ⎤ = W ⋅ ⎣ ⎢ ⎡ x w y w z w ⎦ ⎥ ⎤ + b = ⎣ ⎢ ⎡ p 1 1 p 2 1 p 3 1 p 1 2 p 2 2 p 3 2 p 1 3 p 2 3 p 3 3 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎡ x w y w z w ⎦ ⎥ ⎤ + ⎣ ⎢ ⎡ p 1 4 p 2 4 p 3 4 ⎦ ⎥ ⎤
在开始解方程之前,通常会将[ x w , y w , z w ] T [x_w,y_w,z_w]^T [ x w , y w , z w ] T X = [ x w , y w , z w , 1 ] T \bm X=[x_w,y_w,z_w,1]^T X = [ x w , y w , z w , 1 ] T
[ x p y p z p ] = [ W ∣ b ] ⋅ [ x w y w z w 1 ] = [ p 11 p 12 p 13 p 14 p 21 p 22 p 23 p 24 p 31 p 32 p 33 p 34 ] ⋅ [ x w y w z w 1 ] = P ⋅ X \left[
\begin{matrix}
x_p\\y_p\\z_p
\end{matrix}
\right]
=
[\bm W|\bm b]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w\\1
\end{matrix}
\right]
=
\left[
\begin{matrix}
p_{11}&p_{12}&p_{13}&p_{14}\\p_{21}&p_{22}&p_{23}&p_{24}\\p_{31}&p_{32}&p_{33}&p_{34}
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w\\1
\end{matrix}
\right]
=\bm P\cdot\bm X
⎣ ⎢ ⎡ x p y p z p ⎦ ⎥ ⎤ = [ W ∣ b ] ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x w y w z w 1 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎡ p 1 1 p 2 1 p 3 1 p 1 2 p 2 2 p 3 2 p 1 3 p 2 3 p 3 3 p 1 4 p 2 4 p 3 4 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x w y w z w 1 ⎦ ⎥ ⎥ ⎥ ⎤ = P ⋅ X
现在开始求解。首先将P \bm P P P = [ p 1 , p 2 , p 3 ] T \bm P=[\bm p_1,\bm p_2,\bm p_3]^T P = [ p 1 , p 2 , p 3 ] T
[ x p y p z p ] = [ p 1 T p 2 T p 3 T ] ⋅ X \left[
\begin{matrix}
x_p\\y_p\\z_p
\end{matrix}
\right]
=
\left[
\begin{matrix}
\bm p_1^T\\\bm p_2^T\\\bm p_3^T
\end{matrix}
\right]
\cdot
\bm X
⎣ ⎢ ⎡ x p y p z p ⎦ ⎥ ⎤ = ⎣ ⎢ ⎡ p 1 T p 2 T p 3 T ⎦ ⎥ ⎤ ⋅ X
于是可得两个约束:
x p z p = p 1 T X p 3 T X y p z p = p 2 T X p 3 T X \begin{aligned}
\frac{x_p}{z_p}&=\frac{\bm p_1^T\bm X}{\bm p_3^T\bm X}\\
\frac{y_p}{z_p}&=\frac{\bm p_2^T\bm X}{\bm p_3^T\bm X}\\
\end{aligned}
z p x p z p y p = p 3 T X p 1 T X = p 3 T X p 2 T X
令u = x p z p u=\frac{x_p}{z_p} u = z p x p v = y p z p v=\frac{y_p}{z_p} v = z p y p
p 1 T X − p 3 T u X = 0 p 2 T X − p 3 T v X = 0 \begin{aligned}
\bm p_1^T\bm X-\bm p_3^Tu\bm X=0\\
\bm p_2^T\bm X-\bm p_3^Tv\bm X=0\\
\end{aligned}
p 1 T X − p 3 T u X = 0 p 2 T X − p 3 T v X = 0
相当于把p 1 T , p 2 T , p 3 T \bm p_1^T,\bm p_2^T,\bm p_3^T p 1 T , p 2 T , p 3 T [ p 1 T , p 2 T , p 3 T ] [\bm p_1^T,\bm p_2^T,\bm p_3^T] [ p 1 T , p 2 T , p 3 T ]
[ p 1 T , p 2 T , p 3 T ] ⋅ [ X 0 0 X − u X − v X ] = [ 0 , 0 ] [\bm p_1^T,\bm p_2^T,\bm p_3^T]
\cdot
\left[
\begin{matrix}
\bm X&\bm 0\\
\bm 0&\bm X\\
-u\bm X&-v\bm X\\
\end{matrix}
\right]
=[0,0]
[ p 1 T , p 2 T , p 3 T ] ⋅ ⎣ ⎢ ⎡ X 0 − u X 0 X − v X ⎦ ⎥ ⎤ = [ 0 , 0 ]
转置一下:
[ X T 0 − u X T 0 X T − v X T ] ⋅ [ p 1 p 2 p 3 ] = [ 0 0 ] \left[
\begin{matrix}
\bm X^T&\bm 0&-u\bm X^T\\
\bm 0&\bm X^T&-v\bm X^T\\
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
\bm p_1\\\bm p_2\\\bm p_3
\end{matrix}
\right]
=
\left[
\begin{matrix}
0\\0
\end{matrix}
\right]
[ X T 0 0 X T − u X T − v X T ] ⋅ ⎣ ⎢ ⎡ p 1 p 2 p 3 ⎦ ⎥ ⎤ = [ 0 0 ]
于是,如果有N N N X 1 , … , X N \bm X_1,\dots,\bm X_N X 1 , … , X N N N N
[ X 1 T 0 − u 1 X 1 T 0 X 1 T − v 1 X 1 T ⋮ ⋮ ⋮ X N T 0 − u N X N T 0 X N T − v N X N T ] ⋅ [ p 1 p 2 p 3 ] = [ 0 0 ⋮ 0 0 ] \left[
\begin{matrix}
\bm X_1^T&\bm 0&-u_1\bm X_1^T\\
\bm 0&\bm X_1^T&-v_1\bm X_1^T\\
\vdots&\vdots&\vdots\\
\bm X_N^T&\bm 0&-u_N\bm X_N^T\\
\bm 0&\bm X_N^T&-v_N\bm X_N^T\\
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
\bm p_1\\\bm p_2\\\bm p_3
\end{matrix}
\right]
=
\left[
\begin{matrix}
0\\0\\\vdots\\0\\0
\end{matrix}
\right]
⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ X 1 T 0 ⋮ X N T 0 0 X 1 T ⋮ 0 X N T − u 1 X 1 T − v 1 X 1 T ⋮ − u N X N T − v N X N T ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ ⋅ ⎣ ⎢ ⎡ p 1 p 2 p 3 ⎦ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 0 ⋮ 0 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
由于 [ p 1 T , p 2 T , p 3 T ] [\bm p_1^T,\bm p_2^T,\bm p_3^T] [ p 1 T , p 2 T , p 3 T ] 最少通过六对匹配点 (12条方程),即可实现参数矩阵 [ R ∣ t ] [\bm R|\bm t] [ R ∣ t ]
这里应用SVD 简单来说就是:
m i n x ∥ A x ∥ 2 s . t . ∥ x ∥ = 1 \begin{aligned}
&&\mathop{min}\limits_{\bm x}\|\bm A\bm x\|^2\\
s.t.&&\|\bm x\|=1
\end{aligned}
s . t . x min ∥ A x ∥ 2 ∥ x ∥ = 1
其中:
A = [ X 1 T 0 − u 1 X 1 T 0 X 1 T − v 1 X 1 T ⋮ ⋮ ⋮ X N T 0 − u N X N T 0 X N T − v N X N T ] A=
\left[
\begin{matrix}
\bm X_1^T&\bm 0&-u_1\bm X_1^T\\
\bm 0&\bm X_1^T&-v_1\bm X_1^T\\
\vdots&\vdots&\vdots\\
\bm X_N^T&\bm 0&-u_N\bm X_N^T\\
\bm 0&\bm X_N^T&-v_N\bm X_N^T\\
\end{matrix}
\right]
A = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ X 1 T 0 ⋮ X N T 0 0 X 1 T ⋮ 0 X N T − u 1 X 1 T − v 1 X 1 T ⋮ − u N X N T − v N X N T ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
x = [ p 1 p 2 p 3 ] \bm x=
\left[
\begin{matrix}
\bm p_1\\\bm p_2\\\bm p_3
\end{matrix}
\right]
x = ⎣ ⎢ ⎡ p 1 p 2 p 3 ⎦ ⎥ ⎤
求解过程参照SVD 中的介绍即可,最终可以解得P \bm P P
进一步,P \bm P P
P = K [ R ∣ t ] = [ f x 0 c x 0 f y c y 0 0 1 ] ⋅ [ r 11 r 12 r 13 t 1 r 21 r 22 r 23 t 2 r 31 r 32 r 33 t 3 ] \bm P=\bm K[\bm R|\bm t]=
\left[
\begin{matrix}
f_x&0&c_x\\0&f_y&c_y\\0&0&1
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&t_3
\end{matrix}
\right]
P = K [ R ∣ t ] = ⎣ ⎢ ⎡ f x 0 0 0 f y 0 c x c y 1 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎡ r 1 1 r 2 1 r 3 1 r 1 2 r 2 2 r 3 2 r 1 3 r 2 3 r 3 3 t 1 t 2 t 3 ⎦ ⎥ ⎤
于是具体世界坐标系坐标值到相机坐标系坐标值的计算公式为:
[ x p y p z p ] = K [ R ∣ t ] ⋅ [ x w y w z w 1 ] = [ f x 0 c x 0 f y c y 0 0 1 ] ⋅ [ r 11 r 12 r 13 t 1 r 21 r 22 r 23 t 2 r 31 r 32 r 33 t 3 ] ⋅ [ x w y w z w 1 ] \left[
\begin{matrix}
x_p\\y_p\\z_p
\end{matrix}
\right]
=
\bm K[\bm R|\bm t]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w\\1
\end{matrix}
\right]
=
\left[
\begin{matrix}
f_x&0&c_x\\0&f_y&c_y\\0&0&1
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&t_3
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
x_w\\y_w\\z_w\\1
\end{matrix}
\right]
⎣ ⎢ ⎡ x p y p z p ⎦ ⎥ ⎤ = K [ R ∣ t ] ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x w y w z w 1 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎡ f x 0 0 0 f y 0 c x c y 1 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎡ r 1 1 r 2 1 r 3 1 r 1 2 r 2 2 r 3 2 r 1 3 r 2 3 r 3 3 t 1 t 2 t 3 ⎦ ⎥ ⎤ ⋅ ⎣ ⎢ ⎢ ⎢ ⎡ x w y w z w 1 ⎦ ⎥ ⎥ ⎥ ⎤
其中这个增广矩阵[ R ∣ t ] [\bm R|\bm t] [ R ∣ t ] K \bm K K
进一步深入:分解相机参数P = K [ R ∣ t ] \bm P=\bm K[\bm R|\bm t] P = K [ R ∣ t ] 相机内参K \bm K K R \bm R R t \bm t t P \bm P P P \bm P P
在 DLT 求解中,我们直接将 [ R ∣ t ] [\bm R|\bm t] [ R ∣ t ] R ∈ S O ( 3 ) \bm R\in SO(3) R ∈ S O ( 3 ) R R R [ R ∣ t ] [\bm R|\bm t] [ R ∣ t ] 3 × 3 3\times 3 3 × 3 S E ( 3 ) SE(3) S E ( 3 )
首先把P \bm P P
P = K [ R ∣ t ] = [ K R ∣ K t ] = [ H ∣ h ] \bm P=\bm K[\bm R|\bm t]=[\bm K\bm R|\bm K\bm t]=[\bm H|\bm h]
P = K [ R ∣ t ] = [ K R ∣ K t ] = [ H ∣ h ]
所以P \bm P P H = K R \bm H=\bm K\bm R H = K R h = K t \bm h=\bm K\bm t h = K t
观察H = K R \bm H=\bm K\bm R H = K R K \bm K K R \bm R R
H − 1 = R − 1 K − 1 = R T K − 1 \bm H^{-1}=\bm R^{-1}\bm K^{-1}=\bm R^T\bm K^{-1}
H − 1 = R − 1 K − 1 = R T K − 1
因此,对H − 1 \bm H^{-1} H − 1 R T \bm R^T R T K − 1 \bm K^{-1} K − 1 K \bm K K R \bm R R
t = K − 1 h \bm t=\bm K^{-1}\bm h
t = K − 1 h
结束了?并不。理想很丰满,现实很骨感。QR分解:
不保证K 3 , 3 = 1 \bm K_{3,3}=1 K 3 , 3 = 1 不保证K 0 , 0 > 0 K_{0,0}>0 K 0 , 0 > 0 K 1 , 1 > 0 K_{1,1}>0 K 1 , 1 > 0 不保证K 1 , 2 = 0 K_{1,2}=0 K 1 , 2 = 0 所以在t = K − 1 h \bm t=\bm K^{-1}\bm h t = K − 1 h
令K 3 , 3 = 1 \bm K_{3,3}=1 K 3 , 3 = 1 K ^ = K / K 3 , 3 \hat{\bm K}=\bm K/\bm K_{3,3} K ^ = K / K 3 , 3 为什么可以直接除?回忆相机参数与坐标系变换 中的内容,对矩阵K \bm K K z p K z_p\bm K z p K z p [ u , v , 1 ] T z_p[u,v,1]^T z p [ u , v , 1 ] T z p z_p z p 令K 0 , 0 > 0 K_{0,0}>0 K 0 , 0 > 0 K 1 , 1 > 0 K_{1,1}>0 K 1 , 1 > 0 R ( z , π ) \bm R(z, \pi) R ( z , π ) K ^ = K R ( z , π ) \hat{\bm K}=\bm K\bm R(z, \pi) K ^ = K R ( z , π ) R ^ = R ( z , π ) R \hat{\bm R}=\bm R(z, \pi)\bm R R ^ = R ( z , π ) R 令K 1 , 2 = 0 K_{1,2}=0 K 1 , 2 = 0 QR分解得到的上三角矩阵可能是这样的:
K = [ f x c o t ( θ ) c x 0 f y c y 0 0 1 ] \bm K
=
\left[
\begin{matrix}
f_x&cot(\theta)&c_x\\0&f_y&c_y\\0&0&1
\end{matrix}
\right]
K = ⎣ ⎢ ⎡ f x 0 0 c o t ( θ ) f y 0 c x c y 1 ⎦ ⎥ ⎤
这里的c o t ( θ ) cot(\theta) c o t ( θ ) θ \theta θ c o t ( θ ) = 0 cot(\theta)=0 c o t ( θ ) = 0
c o t ( θ ) cot(\theta) c o t ( θ )
进一步深入:分解相机参数P = K [ R ∣ t ] \bm P=\bm K[\bm R|\bm t] P = K [ R ∣ t ]
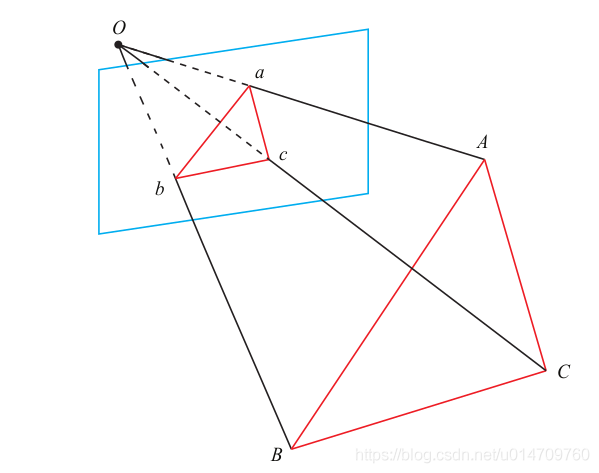
P3P算法 PnP(Perspective-n-Point)是求解 3D 到 2D 点对运动的方法。它描述了当我们知道n n n
通俗的讲,PnP问题就是在已知世界坐标系下n n n
上述已知多个点求解相机位姿的问题也被称为 “PnP问题” ,而DLT是求解PnP问题的多种方法中的其中一种。
接下来要介绍的P3P算法只利用三个点的信息进行求解,其缺点是不能利用更多点的信息,优点是不需要SVD所以计算速度快。
P3P 顾名思义n = 3 n=3 n = 3 A , B , C A, B, C A , B , C a , b , c a, b, c a , b , c D − d D-d D − d O O O A , B , C A, B, C A , B , C 世界坐标系中的坐标 ,而不是在相机坐标系中的坐标 。
首先,显然,三角形之间存在对应关系:
Δ O a b − Δ O A B , Δ O b c − Δ O B C , Δ O a c − Δ O A C \Delta Oab - \Delta OAB, \quad \Delta Obc - \Delta OBC, \quad \Delta Oac - \Delta OAC
Δ O a b − Δ O A B , Δ O b c − Δ O B C , Δ O a c − Δ O A C
对于三角形 O a b Oab O a b O A B OAB O A B
O A ‾ 2 + O B ‾ 2 − 2. O A ‾ . O B ‾ . cos ⟨ a , b ⟩ = A B ‾ 2 O B ‾ 2 + O C ‾ 2 − 2. O B ‾ . O C ‾ . cos ⟨ b , c ⟩ = B C ‾ 2 O A ‾ 2 + O C ‾ 2 − 2. O A ‾ . O C ‾ . cos ⟨ a , c ⟩ = A C ‾ 2 \begin{array}{l}
\overline{OA}^2 + \overline{OB}^2 - 2.\overline{OA}.\overline{OB}.\cos \left\langle a,b \right \rangle = \overline{AB}^2\\
\overline{OB}^2 + \overline{OC}^2 - 2.\overline{OB}.\overline{OC}.\cos \left\langle b,c \right \rangle = \overline{BC}^2\\
\overline{OA}^2 + \overline{OC}^2 - 2.\overline{OA}.\overline{OC}.\cos \left\langle a,c \right \rangle = \overline{AC}^2
\end{array}
O A 2 + O B 2 − 2 . O A . O B . cos ⟨ a , b ⟩ = A B 2 O B 2 + O C 2 − 2 . O B . O C . cos ⟨ b , c ⟩ = B C 2 O A 2 + O C 2 − 2 . O A . O C . cos ⟨ a , c ⟩ = A C 2
对上面三式全体除以 O C ‾ 2 \overline{OC}^2 O C 2 x = O A ‾ / O C ‾ , y = O B ‾ / O C ‾ x=\overline{OA}/\overline{OC},\ y=\overline{OB}/\overline{OC} x = O A / O C , y = O B / O C
x 2 + y 2 − 2. x . y . cos ⟨ a , b ⟩ = A B ‾ 2 / O C ‾ 2 y 2 + 1 2 − 2. y . cos ⟨ b , c ⟩ = B C ‾ 2 / O C ‾ 2 x 2 + 1 2 − 2. x . cos ⟨ a , c ⟩ = A C ‾ 2 / O C ‾ 2 \begin{array}{l}
{x^2} + {y^2} - 2.x.y.\cos \left\langle a,b \right \rangle = \overline{AB}^2/\overline{OC}^2\\
{y^2} + {1^2} - 2.y.\cos \left\langle b,c \right \rangle = \overline{BC}^2/\overline{OC}^2\\
{x^2} + {1^2} - 2.x.\cos \left\langle a,c \right \rangle = \overline{AC}^2/\overline{OC}^2
\end{array}
x 2 + y 2 − 2 . x . y . cos ⟨ a , b ⟩ = A B 2 / O C 2 y 2 + 1 2 − 2 . y . cos ⟨ b , c ⟩ = B C 2 / O C 2 x 2 + 1 2 − 2 . x . cos ⟨ a , c ⟩ = A C 2 / O C 2
记 v = A B ‾ 2 / O C ‾ 2 , u . v = B C ‾ 2 / O C ‾ 2 , w . v = A C ‾ 2 / O C ‾ 2 v = \overline{AB}^2/\overline{OC}^2,\ u.v = \overline{BC}^2/\overline{OC}^2,\ w.v = \overline{AC}^2/\overline{OC}^2 v = A B 2 / O C 2 , u . v = B C 2 / O C 2 , w . v = A C 2 / O C 2
x 2 + y 2 − 2. x . y . cos ⟨ a , b ⟩ − v = 0 y 2 + 1 2 − 2. y . cos ⟨ b , c ⟩ − u . v = 0 x 2 + 1 2 − 2. x . cos ⟨ a , c ⟩ − w . v = 0 \begin{array}{l}
{x^2} + {y^2} - 2.x.y.\cos \left\langle a,b \right \rangle - v = 0\\
{y^2} + {1^2} - 2.y.\cos \left\langle b,c \right \rangle - u.v = 0\\
{x^2} + {1^2} - 2.x.\cos \left\langle a,c \right \rangle - w.v = 0
\end{array}
x 2 + y 2 − 2 . x . y . cos ⟨ a , b ⟩ − v = 0 y 2 + 1 2 − 2 . y . cos ⟨ b , c ⟩ − u . v = 0 x 2 + 1 2 − 2 . x . cos ⟨ a , c ⟩ − w . v = 0
我们可以把第一个式子中的 v v v
( 1 − u ) y 2 − u x 2 − 2 cos ⟨ b , c ⟩ y + 2 u x y cos ⟨ a , b ⟩ + 1 = 0 ( 1 − w ) x 2 − w y 2 − 2 cos ⟨ a , c ⟩ x + 2 w x y cos ⟨ a , b ⟩ + 1 = 0. \begin{array}{l}
\left( {1 - u} \right){y^2} - u{x^2} - 2 \cos \left\langle b,c \right \rangle y + 2uxy\cos \left\langle a,b \right \rangle + 1 = 0 \\
\left( {1 - w} \right){x^2} - w{y^2} - 2 \cos \left\langle a,c \right \rangle x + 2wxy\cos \left\langle a,b \right \rangle + 1 = 0.
\end{array}
( 1 − u ) y 2 − u x 2 − 2 cos ⟨ b , c ⟩ y + 2 u x y cos ⟨ a , b ⟩ + 1 = 0 ( 1 − w ) x 2 − w y 2 − 2 cos ⟨ a , c ⟩ x + 2 w x y cos ⟨ a , b ⟩ + 1 = 0 .
由于我们知道 2D 点的图像位置,三个余弦角cos ⟨ a , b ⟩ \cos \left \langle a,b \right \rangle cos ⟨ a , b ⟩ cos ⟨ b , c ⟩ \cos \left\langle b,c \right \rangle cos ⟨ b , c ⟩ cos ⟨ a , c ⟩ \cos \left \langle a,c \right \rangle cos ⟨ a , c ⟩ u = B C ‾ 2 / A B ‾ 2 , w = A C ‾ 2 / A B ‾ 2 u=\overline{BC}^2/\overline{AB}^2, w=\overline{AC}^2/\overline{AB}^2 u = B C 2 / A B 2 , w = A C 2 / A B 2 A , B , C A, B, C A , B , C x x x y y y
因此,P3P问题最终可以转换成关于 x, y 的一个二元二次方程(多项式方程)
该方程最多可能得到四个解 ,但我们可以用验证点来计算最可能的解,得到 A , B , C A, B, C A , B , C
PnP算法的缺陷 P3P 也存在着一些问题:
P3P 只利用三个点的信息。当给定的配对点多于 3 组时,难以利用更多的信息。 如果 3D 点或 2D 点受噪声影响,或者存在误匹配,则算法失效。
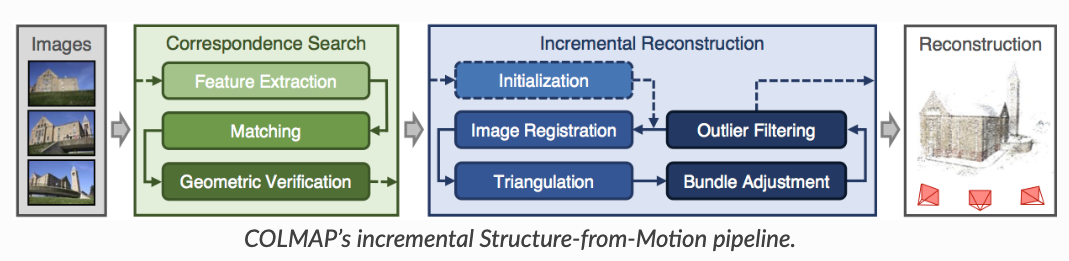
所以后续人们还提出了许多别的方法,如 EPnP、 UPnP 等。它们利用更多的信息,而且用迭代的方式对相机位姿进行优化,以尽可能地消除噪声的影响。 用Colmap进行SFM 对于真实场景,比如我们用手机拍摄了一组图像,怎么获得相机位姿?目前常用的方法是利用运动恢复结构(structure-from-motion, SFM)技术估计几个相机间的相对位姿。这个技术比较成熟了,现在学术界里用的比较多的开源软件包是COLMAP: https://colmap.github.io/ 。输入多张图像,COLMAP可以估计出相机的内参和外参(也就是sparse model)。
具体介绍
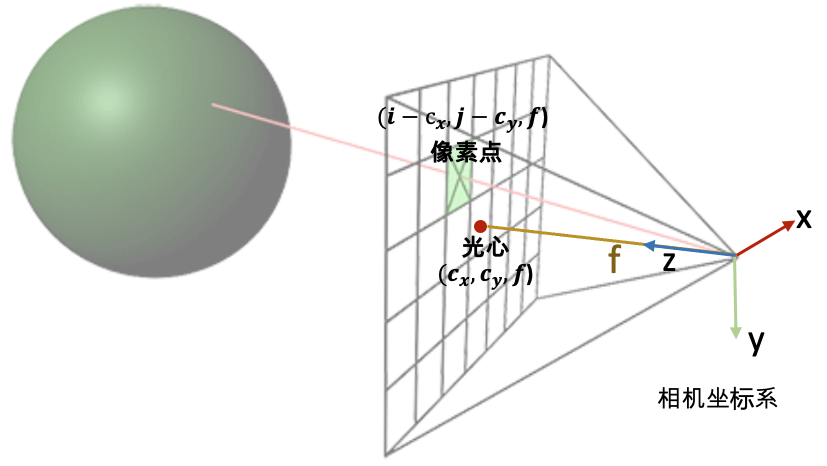
3D空间射线怎么构造 最后我们看一下这个射线是怎么构造的。 给定一张图像的一个像素点,我们的目标是构造以相机中心为起始点,经过相机中心和像素点的射线。
首先,明确两件事:
一条射线包括一个起始点和一个方向,起点的话就是相机中心。对于射线方向,我们都知道两点确定一条直线,所以除了相机中心我们还需另一个点,而这个点就是成像平面的像素点。 NeRF代码是在相机坐标系下构建射线,然后再通过camera-to-world (c2w)矩阵将射线变换到世界坐标系。 通过上述的讨论,我们第一步是要先写出相机中心和像素点在相机坐标系的3D坐标。下面我们以OpenCV/Colmap的相机坐标系为例介绍。相机中心的坐标很明显就是[ 0 , 0 , 0 ] [0,0,0] [ 0 , 0 , 0 ] ( i , j ) (i, j) ( i , j ) ( c x , c y ) (c_x,c_y) ( c x , c y ) f f f f f f
所以我们就可以得到射线的方向向量是 [ i − c x , j − c y , f ] − [ 0 , 0 , 0 ] = [ i − c x , j − c y , f ] [i-c_x, j-c_y, f] - [0, 0, 0] = [i-c_x, j-c_y, f] [ i − c x , j − c y , f ] − [ 0 , 0 , 0 ] = [ i − c x , j − c y , f ] f f f ( i − c x f , j − c y f , 1 ) (\frac{i-c_x}{f}, \frac{j-c_y}{f}, 1) ( f i − c x , f j − c y , 1 )
接着只需要用c2w矩阵把相机坐标系下的相机中心和射线方向变换到世界坐标系就搞定了。
下面是NeRF的实现代码。但关于这里面有一个细节需要注意一下:为什么函数的第二行中dirs的y和z的方向值需要乘以负号,和我们刚刚推导的的 ( i − c x f , j − c y f , 1 ) (\frac{i-c_x}{f}, \frac{j-c_y}{f}, 1) ( f i − c x , f j − c y , 1 )
def get_rays_np ( H, W, K, c2w) :
i, j = np. meshgrid( np. arange( W, dtype= np. float32) , np. arange( H, dtype= np. float32) , indexing= 'xv)
dirs = np. stack( [ ( i- K[ 0 ] [ 2 ] ) / K[ 0 ] [ 0 ] , - ( j- K[ 1 ] [ 2 ] ) / K[ 1 ] [ 1 ] , - np. ones_like( i) ] , - 1 )
rays_d = np. sum ( dirs[ . . . , np. newaxis, : ] * c2w[ : 3 , : 3 ] , - 1 )
rays_o = np. broadcast_to( c2w[ : 3 , - 1 ] , np. shape( rays_d) )
return rays_o, rays_d
1 2 3 4 5 6 7 8
这是因为OpenCV/Colmap的相机坐标系里相机的Up/Y朝下, 相机光心朝向+Z轴,而NeRF/OpenGL相机坐标系里相机的Up/朝上,相机光心朝向-Z轴,所以这里代码在方向向量dir的第二和第三项乘了个负号。
更多阅读材料: 前面简单地介绍了下NeRF代码中关于相机参数和坐标系变换的内容,这里面有很多细节没有展开介绍,如果有错误还请批评指正。另外,如果初学者希望进一步学习3D、图形学渲染相关的知识,可以浏览下面的一些网站(不全面,仅供参考):
下面是关于NeRF研究方向的一些文章(不全面,仅供参考):