张量分解
前置知识:矩阵分解
相关好书: 相关好书:Low-Rank Tensor Networks for Dimensionality Reduction and Large-Scale Optimization Problems: Perspectives and Challenges PART 1
张量是矩阵的高维扩展:
- 一阶(一维)张量:向量
- 二阶(二维)张量:矩阵
- 三阶(三维)张量:可以看做是多个矩阵堆叠而成,不过由于三阶张量具有三个维度,因此堆叠矩阵的方式也必然存在三种,即水平切片、侧向切片和正面切片:
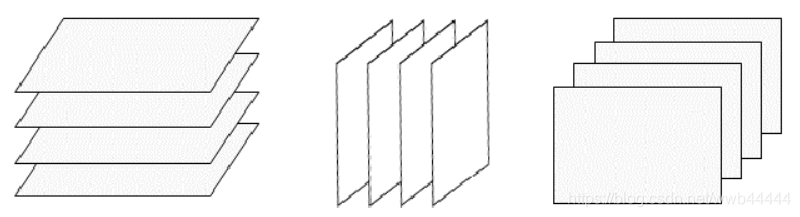
张量的应用面很广,大多数的数据都可用张量表示,例如一张彩色图片就是一个三维张量,分别由像素矩阵和第三维的RGB颜色通道组成。
- 四阶(四维)张量:多张图片组成的一段视频或给神经网络推断输入的一个batch
- 五阶(五维)张量、六阶张量......
矩阵分解是将m×n的矩阵分解为更小的矩阵元素,张量则是将高维矩阵分解为更小的张量元素。
# 秩一张量
若一个N阶张量X∈RI1×I2×⋯×IN能够被表示为N个向量的外积,则称X为秩一张量,即:
X=a1∘a2∘⋯∘aN
这也意味着张量的每个元素都是对应的向量元素的乘积:
xi1,i2…iN=a1,i1a2,i2⋯aN,iN
比如三维的情况X∈a∘b∘c可以画个示意图:
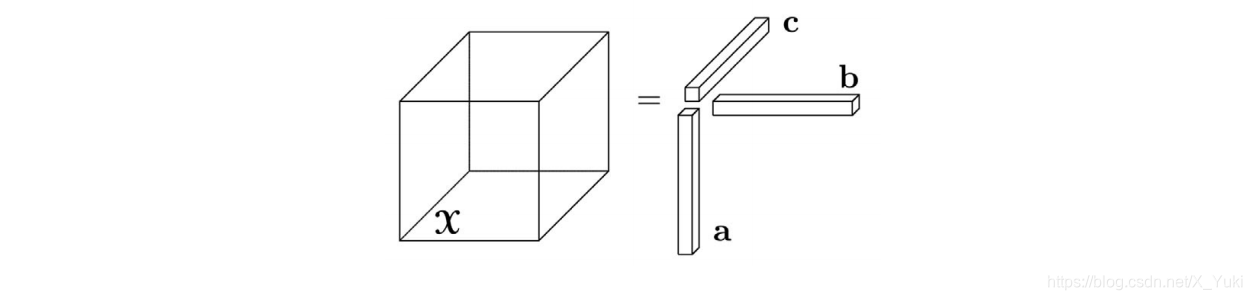
其中xi,j,k=aibjck:
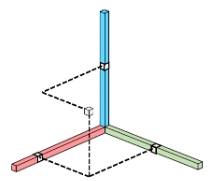
# CP分解 CP decomposition
1927年Hitchcock基于秩一张量的定义,首次提出了将张量拆成有限个秩为1的张量相加的形式。后来在1970年Carrol和Chang将这个概念以CANDECOMP(canonical decomposition,标准分解)的形式在引入到心理测验学当中,与此同时 Harshman也提出了PARAFAC(parallel factors,平行因素)的形式,该方法才得以流行,所以今天我们称这个将张量分解为有限个秩一张量和的形式的分解方法为CP分解,即是CANDECOMP/PARAFAC分解的缩写。
CP分解是将一个高维的张量,分解成多个核的和,每个核是由向量的外积组成;通过这样的分解,我们可以大大地降低参数的维度。其实,不止CP分解,其他的张量分解算法都是同个道理,只是所采用的分解方法不同而已。当然,这样的分解只是原来张量的近似,没办法保证完全复原。从以上角度来说,张量分解的目的跟矩阵分解是相同的,只是一个是在二维上的分解,另一个是在高维上的分解而已!
简单来说,CP分解就是将一个N阶张量分解成多个秩一张量之和的形式:
X≈r=1∑Rar,1∘ar,2∘⋯∘ar,N
比如一个三维张量X分解为R个秩一张量和:

即:
X≈r=1∑Rar∘br∘cr
于是X中的元素为:
xi,j,k≈r=1∑Rar,ibr,jcr,k
# CP秩
张量X的秩,用秩一张量之和来精确表示所需要的秩一张量的最少个数R的最小值为张量的秩,记作RankCP(X)=R,这样的CP分解也称为张量的秩分解。
RankCP(X)=min{R∣X=r=1∑Rar,1∘ar,2∘⋯∘ar,N}
显然,这样定义的张量秩和矩阵的秩的定义十分相似,可以证明二阶张量秩和矩阵的秩等价。 但是在代数性质上,张量的秩与矩阵秩相比则表现出很多不一样的特性。张量秩的个数求解是一个NP问题,研究者只能通过一些数值方法近似的找到数个该张量的近似分解,从而估计该张量的秩。
# CP分解算法
当数据无噪声时,通常通过迭代的方法对R从1开始遍历直到找到一个重构误差为0的R。
当数据有噪声时,可以通过CORCONDIA算法估计R。
当R确定之后,可以通过交替最小二乘方法(the Alternating Least Squares,ALS)求解CP分解:

看不懂一点😂
在一些应用中,为了使得CP分解更加的鲁棒和精确,可以在分解出的因子上加上一些先验知识即约束。比如说平滑约束(smooth)、正交约束、非负约束(nonegative) 、稀疏约束(sparsity)等。
# Tucker 分解 Tucker decomposition
Tucker分解最早由Tucker在1963年提出的,Levin和Tucker在随后的文章中对其进行了改进。 张量的Tucker分解在将一个张量表示成一个核张量(Core Tensor)沿着每一个模式乘上一个矩阵的形式。
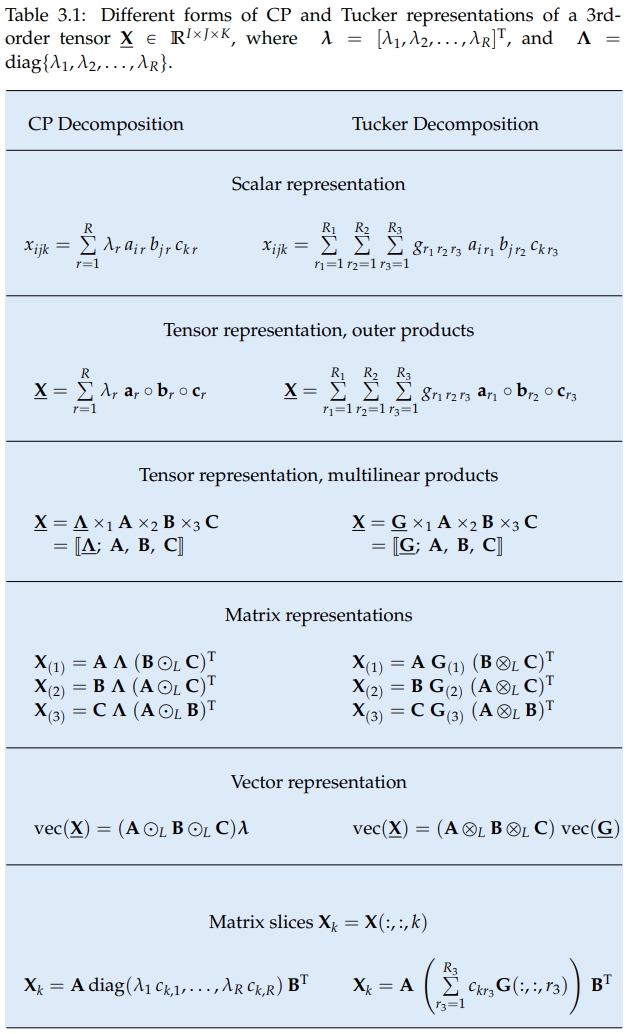
# 从CP分解到Tucker分解
作为对比,给CP分解的秩一矩阵加上一个系数,也可以表示为一个核张量和乘上一个矩阵的形式:

直接上图:
# t-SVD分解
t-SVD分解是建立在新定义的张量积(t-product)基础上的新的分解框架,主要针对三维张量数据的分解。